Loop Engineering: New Paradigm or Rebranded Cron? (2026)

The man who runs Claude Code at Anthropic says he doesn't prompt Claude anymore. "I have loops running that prompt Claude... My job is to write loops." Within a week, loop engineering went from a phrase nobody used to the loudest conversation in AI development — and if you work anywhere near AI coding agents, you've probably seen the takes flying past.
So is this a genuine shift in how we work with AI, or another buzzword on the pile? I've spent 30 years automating security work, and I've watched a lot of "new paradigms" turn out to be old ideas with better marketing. This one is partly that — but there's a genuinely useful idea buried underneath.
In this article, we'll look at where the hype came from, boil loop engineering down to one sentence, walk through real examples of where it works, and give you a simple test for whether it's worth your time.
From Prompt Engineering to Loop Engineering: Where the Hype Comes From
The timeline here is remarkably short. On 7 June 2026, Peter Steinberger — the developer behind OpenClaw — posted what he called his "monthly reminder": "you shouldn't be prompting coding agents anymore. You should be designing loops that prompt your agents." He'd been posting variants of that line since May; this was the one that caught, and it was viewed millions of times within days. Boris Cherny, head of Claude Code at Anthropic, had been saying the same thing for weeks — the quote you opened with comes from an interview that was already doing the rounds. The same day as Steinberger's post, Google engineer Addy Osmani published an essay that organised the idea into something teachable, and the term stuck.
If you're feeling déjà vu, you're not imagining it. We've been through prompt engineering, then context engineering, then harness engineering. Each rebrand gets its own hype cycle, and each one claims the previous skill is obsolete. That alone is a good reason to be sceptical.
But there's a practical reason this one caught fire now. Until recently, building an automated agent loop meant writing and maintaining a pile of shell scripts yourself. In the past few months, the building blocks — scheduled agent runs, goal conditions, sub-agents, isolated workspaces — shipped as native features in Claude Code and OpenAI's Codex. (We covered the orchestration side of that wave in our Claude Opus 4.8 review.) The idea isn't new. The cost of doing it just collapsed.

What Is Loop Engineering, Really?
Strip away the discourse, and what is loop engineering? It's this:
A well-defined problem, plus an AI that iterates until a verifiable goal holds.
That's the entire concept. A trigger starts the run. The agent acts — writes code, edits a file, drafts a fix. A checker verifies the result against a goal you defined: do the tests pass, does it compile, is the lint clean. If yes, stop. If no, the failure feeds back in and the agent tries again. A memory file outside the conversation tracks what's done, because the model forgets everything between runs.
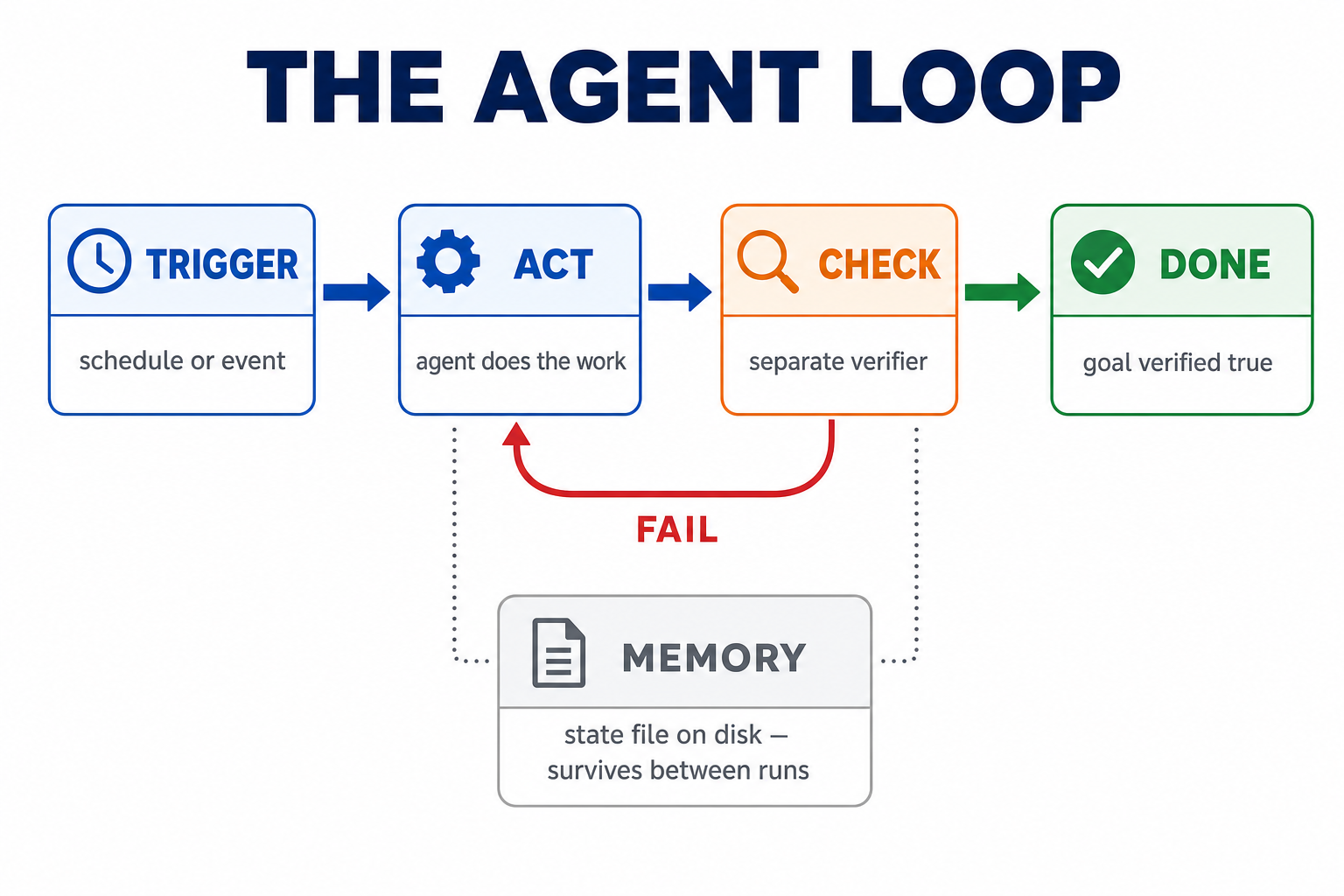
One structural detail matters more than the rest: the agent that does the work should never be the one that grades it. Models are far too generous marking their own homework. Serious setups use a separate verifier — a different agent, or better, something that can't be charmed at all, like a test suite. Claude Code's /goal feature bakes this in: a separate model checks whether your stop condition is actually true after each turn.
If you're thinking "that's a feedback control loop — we've had those for decades," you're right. Test-driven development is a loop. CI retrying until green is a loop. The shape is genuinely old. (Cron, for what it's worth, was only ever the trigger — the real ancestor here is the control loop.) So what's new?
The Genuinely New Thing in AI Agent Automation: Fuzziness Tolerance
Here's the one real conceptual change, and it's worth being precise about it.
Traditional automation needed every step defined. A script does exactly what it's told, and the moment reality deviates — an unexpected input, a renamed field, a weird edge case — it breaks. That's why so much knowledge work never got automated: the goal was clear, but the path couldn't be specified in advance.
AI agent automation flips the contract. You no longer define the steps. You define the finish line, and the intelligence in the loop absorbs the messiness of the path.
A concrete example. "Migrate these 400 call sites to the new API" was never scriptable — each site needs a slightly different change, and a regex can't exercise judgment. But it loops beautifully, because the end state is mechanically checkable: it compiles, and the tests pass. Each call site needs a little intelligence; the outcome needs none at all to verify.
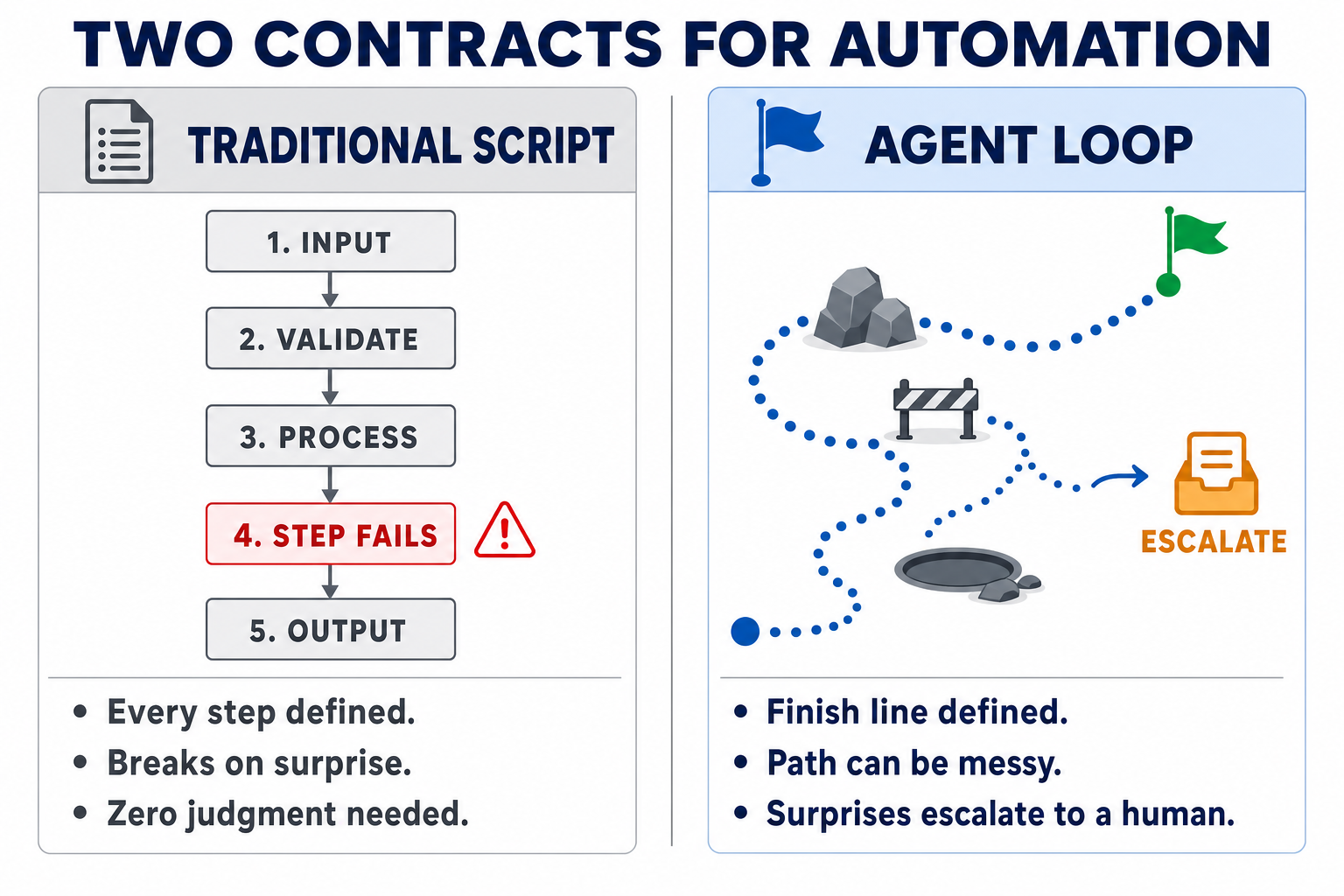
That's the heart of the delta: the contract moved from "define every step" to "define the finish line." Almost everything else you've read about loop engineering is scaffolding around that one idea.
What People Are Actually Running With AI Coding Agents
Claims are cheap, so let's look at what the people quoting results actually run. The pattern across all of them is striking — and it's probably not what the hype led you to expect.
OpenAI uses Codex automations internally for daily issue triage, summarising CI failures, writing commit briefings, and hunting recently introduced bugs. Osmani's description of this work: "boring stuff."
Osmani describes his own daily loop in his essay. Every morning, an automation reads yesterday's CI failures, open issues, and recent commits, and writes findings to a state file. For each finding worth acting on, one sub-agent drafts a fix in an isolated workspace and a second sub-agent reviews it against the tests. The loop opens the pull request. And — this is the important part — anything it can't handle lands in his inbox for a human decision.
Cherny runs a couple of hundred small agents that read his GitHub, Slack, and X and decide what's worth building next. Not one big autonomous developer — hundreds of tiny, bounded loops.
Notice what's missing from every one of these: nobody with credible results to show is looping "build me a feature." The results are real, but they live in discovery, triage, and routine fixes, done at volume. The wins come from three places: the loops find the work — which is honestly a second genuine novelty, since a cron job only ever decided when to run, never what needs doing — the unpredictable gets escalated rather than handled, and the leverage comes from running many small loops rather than one clever one.
Where Agentic Loops Fall Apart
Now for the part the threads tend to skip. I think there are three structural reasons agentic loops don't extend to real development work, and they're worth understanding before you burn a weekend — or a budget — finding out yourself.
First, architecture has no cheap verifier. A loop converges because checking is cheap and objective: tests pass or they don't. "Is this the right design?" has no such check today — and nobody has demonstrated one. Rubric scores and LLM judges can grade what a design looks like; none of them can cheaply tell you it's right. So a loop optimising for green tests will happily produce a well-tested wrong design — and tell you it succeeded.
Second, the spec problem doesn't go away — it moves. To run unattended, a loop needs the goal defined completely up front. But a spec complete enough to leave alone costs roughly as much thought as doing the work, and in real development the spec emerges from building. Anyone who's actually shipped software knows it never goes the way the document said.
Third, mistakes compound silently. When you prompt an agent interactively, you catch the bad assumption on turn two. In a loop, a wrong call on iteration 3 gets forty-seven more iterations built on top of it before you look. The loop doesn't just make mistakes unattended — it invests in them.
And there's a blunt economic constraint underneath all of this: agent workloads consume roughly 4× the tokens of a chat interaction, and multi-agent setups up to 15×. Those figures are one vendor's measurement — treat the exact multiples as indicative — but the direction matches everyone's experience. A runaway loop isn't a hypothetical — it's a billing event. Iteration caps, budget limits, and no-progress detection aren't optional extras; they're the difference between automation and an expensive incident.
It's telling that even Osmani — the person who codified the term — hedges harder than the people quoting him. "It's still early, I'm skeptical," he writes, warning that relying entirely on loops would leave him "stuck in a downward spiral, continuously digging myself into a deeper hole."
The Goal Is Everything
If you take one practical lesson from this article, make it this one: the quality of a loop lives almost entirely in its stop condition.
Compare two goals. "All tests in test/auth pass and lint is clean" — that's checkable. A verifier can confirm it mechanically, and the loop converges on something true. Now try "improve the code quality." What does the checker do with that? It guesses. And an agent iterating against a guessing checker doesn't converge on quality — it converges on plausible-looking output. You haven't automated engineering. You've built a slop factory that runs while you sleep.
This is also the line for when a model is allowed to be the checker. A model verifying a binary, evidence-grounded condition — "do all the tests in test/auth actually pass?" — works, because it's reading evidence, not forming an opinion. A model adjudicating a judgment call — "is the code better?" — is just the agent's optimism wearing a second hat.
This is the irony at the heart of the hype. Loop engineering is sold as the skill that replaces careful prompting — but writing a verifiable goal is defining the problem precisely, which is exactly the work people were hoping to skip. The effort didn't disappear. It moved to the finish line.
Should You Loop It? A One-Line Test
After all of this, the decision comes down to something we can fit in one line. A task is worth looping when it's repeated or high-volume, verifiable, and currently waiting on a human to press go.
"Repeated or high-volume" covers two shapes that loop equally well: the same task recurring over time (nightly validation fixes), and many instances of one shape all at once — those 400 call sites from earlier are a one-off project, but they're four hundred repetitions of the same small judgment. Either way, the effort of designing the loop amortises.
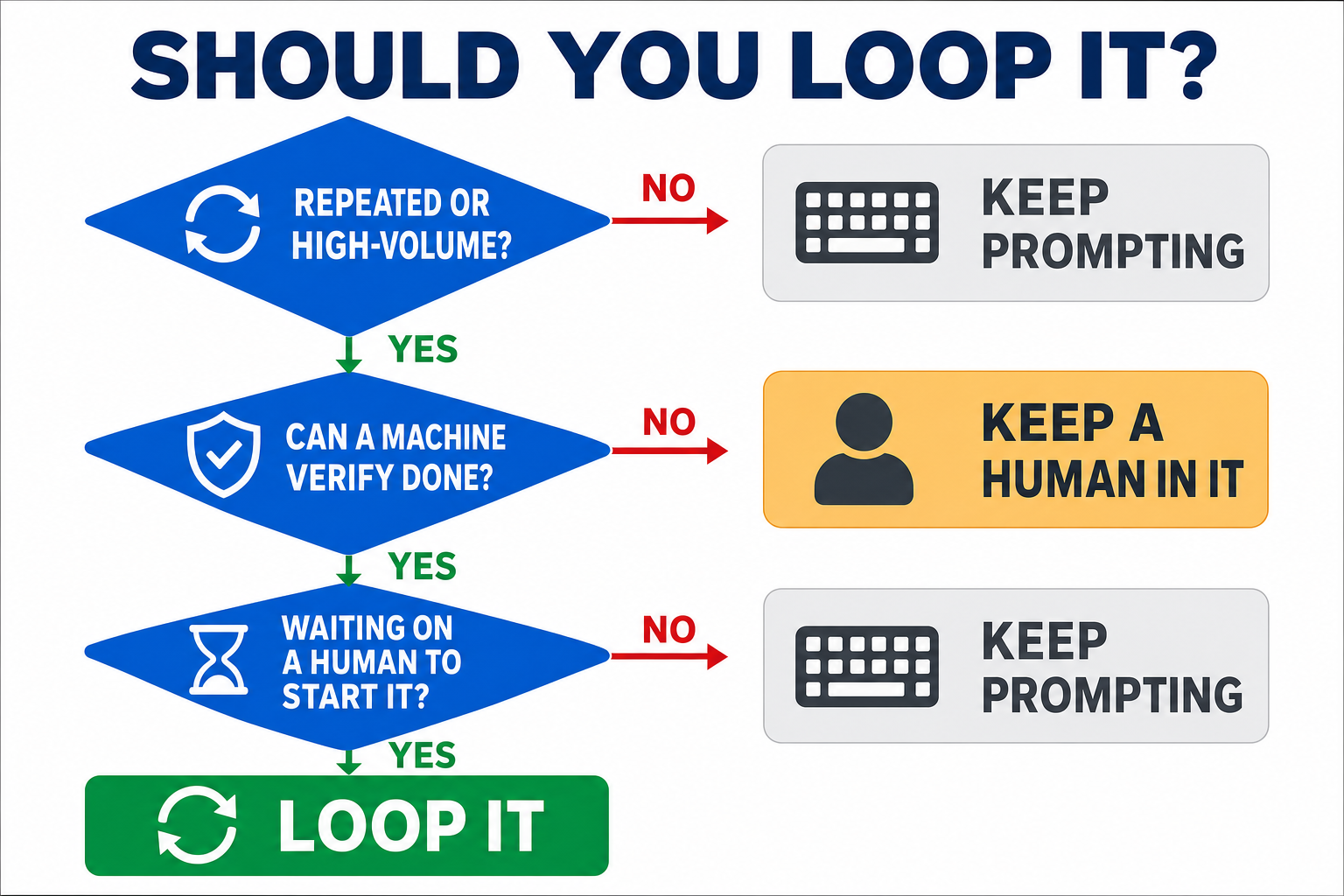
Let's run three cases through it. Nightly "fix whatever the validators flagged" on a content platform: repeated, mechanically checkable, currently waits for a human — loop it. Dependency updates gated on a green build: mostly yes — but notice how narrow "verifiable" turns out to be. Green tests prove the bump didn't break you; they prove nothing about whether the new package is malicious. Supply-chain attacks live precisely in that gap — so loop the routine patch bumps, and keep human review on anything new or unusual. That's not the test failing; that's the test working. "Refactor our architecture": not repeated, no cheap verifier, and the decisions are ones you'd want to be in the room for — keep a human in that loop, however good the agent.
This test is older than the buzzword, by the way. Security teams have been running it for at least fifteen years: a SOAR playbook that enriches an alert, checks the indicators against threat intel, and closes the false positive is a loop with a verifiable finish line. And every SOC that pushed its playbooks past triage into judgment calls learned the same lesson the hard way — automation stops where cheap verification stops. The only edit loop engineering makes to that old rule is relaxing "deterministic" to "verifiable." That's a meaningful relaxation. It is not a revolution.
The Verdict
So: new paradigm or rebranded cron? Honestly — mostly the second, with one real upgrade. The loop itself is an idea engineering has used for half a century. What's new is that the worker inside the loop can now handle ambiguity, which meaningfully widens the set of tasks you can hand to a machine. That's worth having. It's just not worth the messianic framing.
The strongest case for the other side — and it deserves a fair hearing — isn't about the loop at all. It's that cost collapse is how paradigms arrive. Containers were "just" chroot with better tooling; cloud was "just" timesharing; both became genuine shifts because a huge drop in the cost of an old idea changes who can use it and what gets built on top. If agent loops follow that path, the rebrand will have earned itself. Here's why I don't think this is containers: cost collapse widens reach, and reach isn't what bounds agent loops — the verifier is. Writing good tests got no cheaper this year, and "is this the right architecture?" got no easier to check. The boring layer will automate faster and faster; the judgment layer doesn't move with the price.
My advice is to use it the way the people actually getting results use it. Point loops at the boring layer — triage, routine fixes, the backlog nobody loves — where verification is cheap and the blast radius is small. Keep yourself at the gates where judgment lives, the same discipline we teach in AI-driven engineering. And don't let a loop make decisions you wouldn't delegate to a contractor whose work you never review.
Even Osmani lands here: "Build the loop. But build it like someone who intends to stay the engineer, not just the person who presses go." On that much, the sceptics and the evangelists agree.
If you want to build these skills properly — including when not to use them — that's exactly the kind of judgment we teach in the AI Master's Program and our AI courses.
Loop Engineering FAQ
What is loop engineering in simple terms?
Loop engineering is designing a system that prompts an AI agent for you: a trigger starts the agent, a verifier checks its work against a defined goal, and the agent retries until the goal is met or a limit is hit. In one sentence: a well-defined problem plus an AI that iterates until a verifiable goal holds.
Who coined the term loop engineering?
The idea spread in early June 2026 from posts by Peter Steinberger and Boris Cherny (head of Claude Code at Anthropic), and was codified almost immediately in a widely shared essay by Google engineer Addy Osmani. The underlying pattern — agents acting in feedback loops — predates the name by years.
Is loop engineering just prompt engineering with extra steps?
No — it sits a level above. Prompt engineering shapes a single instruction; loop engineering designs the system around the agent: triggers, verification, memory, and stop conditions. The catch is that writing a verifiable goal demands the same precision good prompting did. The work moved; it didn't disappear.
Can loop engineering replace developers?
No. Loops excel at bounded, checkable work — triage, migrations, test-gated fixes — because success can be verified mechanically. Development decisions like architecture have no cheap verifier, and a loop's mistakes compound silently across iterations. Every credible practitioner keeps a human reviewing the output.
What tasks suit an agent loop best?
Tasks that are repeated or high-volume, mechanically verifiable, and currently waiting on a human to start them: fixing whatever a test suite or validator flags, routine dependency bumps gated on green builds, CI-failure triage, and issue summarisation. If you can't write the finish line as a check, don't loop it.
About the Author

Nathan House, Founder & CEO of StationX
Nathan House has 30 years of hands-on cybersecurity experience and is Cambridge-educated, holding CISSP, CISA, CISM, OSCP, CEH, and SABSA. He founded StationX in 1999 — one of the UK’s first cybersecurity companies — and has secured £71 billion in UK mobile banking transactions and the London 2012 Olympics, advising clients including Microsoft, Cisco, BP, Vodafone, and VISA. He authored the world’s most popular cybersecurity course — a #1 Udemy bestseller taken by over 500,000 students — and was named Cyber Security Educator of the Year 2020, AI Security Educator of the Year, and a UK Top 25 Security Influencer 2025. A DEF CON speaker and featured expert on CNN, Fox News, NBC, and the BBC, Nathan leads StationX’s training of more than half a million students worldwide.
