Claude Opus 4.8 Review: Everything New in 2026

Anthropic released Claude Opus 4.8 on 28 May 2026 — six weeks after 4.7. Same $5 input / $25 output pricing, same 1M-token context, same model family. But the defaults have moved again, there's a new way to orchestrate multi-agent work, and the most important change isn't on a benchmark chart — it's that the model is roughly four times less likely to let bad code slide past unmentioned.
I've spent the launch day going through Anthropic's announcement and migration docs, comparing them against my notes from the 4.7 review, and checking what the developer community on Hacker News and X actually thinks (the press take and the dev take diverge sharply).
Here's the structure. First, what shipped. Then four things worth your attention — dynamic workflows, effort control, the honesty jump, and cheaper fast mode. Then the under-the-hood changes, and what I'd do this week.
TL;DR — if you've only got 30 seconds
- What it is: Anthropic's new top model, out 28 May 2026. Same price as 4.7 ($5/$25 per million tokens), same 1M context.
- The big one: About 4× less likely to write buggy code and not tell you — it flags its own uncertainty instead of quietly shipping something that looks right.
- For coders: Better at long, multi-step jobs. New "dynamic workflows" in Claude Code run hundreds of mini-agents in parallel for huge tasks like whole-codebase rewrites.
- For everyone: A new effort dial in the chat app trades "think harder" against "answer faster." Fast mode is now ~3× cheaper.
- Upgrading: Painless. Swap
claude-opus-4-7forclaude-opus-4-8and your setup keeps working. 4.7 isn't going away, so no rush. - The catch: Developers report it can be over-cautious (refusing legitimate work), and the headline benchmark numbers aren't confirmed by Anthropic yet — treat them as provisional.

What Actually Shipped on 28 May
The headline: Opus 4.8 is a coding-and-agentic upgrade with a sharp focus on honesty and long-horizon reliability. Anthropic didn't touch the standard price. Most of the gains are where developers spend their time.
⚠️ Benchmark numbers pending
As of launch day, Anthropic hasn't published an Opus 4.8 system card or a machine-readable benchmark table — the figures on the announcement page are a chart image, and the per-benchmark numbers circulating online are from secondary write-ups. Treat the table below as directional until the official system card lands.
| Benchmark | Opus 4.7 | Opus 4.8 | Source status |
|---|---|---|---|
| SWE-Bench Verified | ~87.6% | ~88.6% | ⚠️ unverified |
| SWE-Bench Pro | ~64.3% | ~69.2% | ⚠️ unverified |
| Terminal-Bench 2.1 | TBC | TBC | ⚠️ no Opus figure |
| GDPval (knowledge work) | ~1753 | ~1890 | ⚠️ unverified |
| Online-Mind2Web (browser agents) | TBC | ~84% | cited in launch post |
Anthropic's announcement renders benchmarks as a chart image; remaining numbers are from secondary coverage pending the official system card. Artificial Analysis independently reported Opus 4.8 as launch-day leader on its GDPval-AA benchmark — that one is third-party-verified, the rest are not.
On agentic terminal coding, Anthropic's own announcement footnote puts GPT-5.5 at 83.4% on Terminal-Bench 2.1 (with the Codex CLI harness) — ahead of Opus on that specific benchmark. Anthropic stating a competitor's lead in their own launch material is itself a small data point about this release.
💡 In plain English
Benchmarks are just standardised tests for AI — like exam scores. 4.8 scores a bit higher than 4.7 on most of them, but Anthropic hasn't published the official marksheet yet, so don't quote these numbers as gospel. The one thing that's clear: it's better at coding and agent work, but ChatGPT's latest still wins one specific coding test.

Dynamic Workflows: Real Multi-Agent Orchestration
Anthropic's biggest user-facing change in Claude Code is dynamic workflows — a research preview that lets a single Opus 4.8 session plan a task, spawn hundreds of subagents in parallel to work on different parts, verify their outputs, and adapt the plan as findings come in.
The "adapt the plan" bit is the new piece. Until 4.7, an agent would write a plan and then execute it even if step 3 revealed step 2 was wrong. Dynamic workflows let Opus 4.8 rewrite the plan mid-run. The canonical example Anthropic give is a codebase-scale migration — point it at a large repository, hand it the spec, and it co-ordinates fan-out work across hundreds of files in one session without losing the thread.
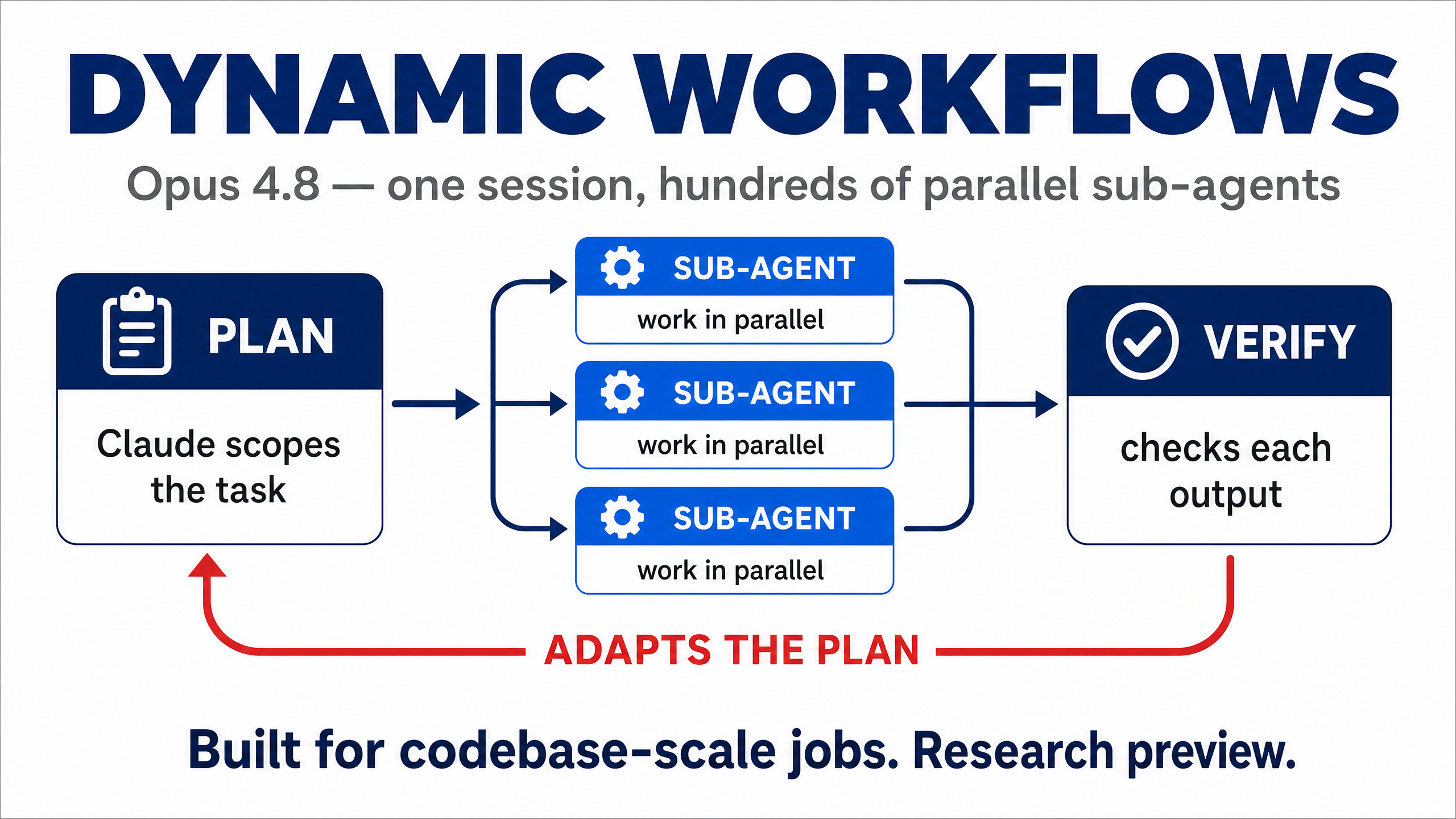
Caveats worth knowing before you try it:
- It's a research preview, not GA. Behaviour will change.
- It's gated to Claude Code specifically — you can't trigger it from the raw API.
- Hundreds of parallel subagents means hundreds of parallel token bills. On Pro/Max plans it eats your usage allowance fast; on the API the cost is real money.
- For genuinely large migrations the throughput is the point. For a single feature on a small repo, you don't need it.
💡 In plain English
Imagine handing a huge job to a manager who instantly hires 100 temps, splits the work between them, checks everyone's output, and changes the plan if something turns out wrong — all in one go. That's dynamic workflows. Brilliant for massive jobs like rewriting an entire codebase; overkill (and pricey) for small ones. It's also still experimental.
Effort Control: The Default Changed, and You Should Know to Which Level
Effort levels — low, medium, high, xhigh, max — tell the model how hard to think. The big change on 4.8 is the default: Anthropic's docs are explicit that effort now defaults to high across all surfaces, including the Claude API and Claude Code. If you set effort explicitly, your setting is left alone; if you didn't, you're on high. For coding and high-autonomy work, Anthropic recommend setting xhigh explicitly — it isn't the default.

Anthropic have also put user-facing effort control into claude.ai and Cowork, so chat users can now trade quality against speed and cost per task without touching a config file.
The levels themselves were recalibrated versus 4.7: medium now allows somewhat more thinking, high somewhat less, and xhigh substantially more. If you tuned a level against 4.7's cost or latency, re-baseline at the same level before adjusting — the numbers behind the label moved.
How to set it on the developer side:
- Per-task in claude.ai / Cowork: the new effort control in the UI.
- In Claude Code TUI:
/effort xhigh(or high/medium/low/max). - Persistent:
"effortLevel": "high"in~/.claude/settings.json. - Environment variable (highest precedence):
export CLAUDE_CODE_EFFORT_LEVEL=high.
💡 In plain English
"Effort" is how hard the AI thinks before answering — more effort means better answers but slower and pricier. 4.8 now has a dial for this in the chat app, and by default it's set to "high" (a sensible middle). If you're doing tricky coding, turn it up to "xhigh" yourself. If you want fast and cheap, turn it down. Just don't assume the factory setting is right for your job.
The Honesty Jump: The Real Headline
If I had to name one thing that changes how it feels to work with Opus 4.8 versus 4.7, it isn't a benchmark. It's that the model has stopped quietly papering over its own mistakes.
Anthropic's wording, verbatim from the launch announcement: Opus 4.8 is "around four times less likely than its predecessor to allow flaws in code it has written to pass unremarked." The framing is that it surfaces uncertainty rather than producing plausible output and stopping.

For anyone using Claude as a coding agent, this is the bit that compounds. The failure mode it targets is familiar: ask the model to fix a bug, get back code that looks right, ship it, then find out later one of the assumptions was wrong and the model never flagged it. A model that says "I assumed X — verify this holds in your codebase" before the change goes in is worth more, day to day, than a couple of benchmark points. Worth testing against your own work before you take the 4× at face value — it's Anthropic's number, not yet independently reproduced.
My honest caveat: Anthropic's safety-side training has come with collateral damage in recent Opus releases. Hacker News on launch day is full of developers complaining about over-eager refusals (the "malware reminder" pattern), shorter responses, and at least one report of a bug causing a sharp spend increase on the same task. The honesty improvement is real. The over-cautious refusal pattern is also real. Watch both.
💡 In plain English
The old model would sometimes write code with a hidden flaw and say nothing — like a builder who quietly bodges a join and hopes you won't notice. The new one is far more likely to say "I wasn't sure about this bit, check it." That honesty is worth more in everyday use than a slightly higher test score. (Anthropic's own words, though — not yet independently proven, so verify it on your own work.)
Fast Mode Is Now Actually Affordable
Fast mode — the higher-priced, lower-latency variant — existed on 4.7 but was eye-wateringly expensive. On 4.8, Anthropic have dropped the price meaningfully:
- Standard pricing: $5 input / $25 output per million tokens (unchanged).
- Fast mode pricing: $10 input / $50 output per million tokens — about 3× cheaper than 4.7's fast mode, and roughly 2.5× faster than standard.
On multimodal cost, Anthropic cite one customer — Databricks Genie — running Opus 4.8 at a 61% cheaper token cost than Opus 4.7 on their multimodal workload. Read that as a case-study data point, not a blanket published rate cut: your mileage depends on your own mix of text and images. Still, if you've been pricing out a document-heavy workflow, it's worth re-running the numbers.
Same warning as last release: list price isn't the whole story. The 4.7 tokenizer change pushed effective costs up 0-35% on the same prompts. Watch your first week of billing before treating the headline numbers as gospel.
💡 In plain English
"Fast mode" is the express lane — same model, quicker answers, but you pay extra. On 4.7 that extra was painful; on 4.8 it's about a third of what it was, so it's now worth using when speed matters. And if your work involves lots of PDFs or images, one customer found it noticeably cheaper to run — worth checking your own numbers.
Under-the-Hood Changes Worth Knowing
Three smaller changes that aren't headline features but will catch you out if you don't know about them.
Mid-conversation role: "system" messages now work. On 4.7 you could only set a system message at the start. On 4.8 the API accepts role: "system" messages within the messages array after a user turn, which lets you inject new instructions partway through a session without restarting the conversation. Useful for multi-turn agents that need to switch persona or constraints mid-task.
Lower prompt caching minimum. Anthropic's migration guide states the minimum cacheable prompt length on 4.8 is 1,024 tokens — lower than on 4.7 (they don't publish 4.7's exact figure, only that 4.8's is lower). Prompts that were previously too short to cache can now create cache entries with no code changes. That puts the cost saving in reach of short-context callers (chat UIs, fast-turn agents), not just long-context document work.
No breaking API changes. Your 4.7 code runs unchanged on 4.8 — just swap claude-opus-4-7 to claude-opus-4-8 in the model field. Unlike the 4.6→4.7 migration, you don't need to refactor thinking parameters or worry about budget tokens disappearing.
One thing to watch: Anthropic haven't deprecated 4.7 — it's listed as a legacy-but-available model with no published retirement date (the only Opus/Sonnet models on a retirement clock right now are the original Claude 4 pair, going on 15 June 2026). So if you've tuned prompts, evals, or downstream tooling for 4.7's specific behaviour, you can stay on it without a forced cutover.
💡 In plain English
This section is for developers wiring Claude into their own software — skip it if that's not you. The short version: upgrading is painless (change one line, nothing breaks), there are a couple of new conveniences for programmers, and your old 4.7 setup will keep working for the foreseeable future.
Should You Upgrade?

| If you mainly... | Use |
|---|---|
| Write code and use agents | 4.8 — the honesty jump is the killer feature |
| Run codebase-scale migrations | 4.8 — dynamic workflows are why it exists |
| Drive browser/computer-use automation | 4.8 — the reported Online-Mind2Web result is the standout |
| Read lots of PDFs/diagrams (multimodal) | 4.8 — one customer saw 61% cheaper; re-run your own numbers |
| Have heavily tuned 4.7 prompts and evals | Stay on 4.7 — supported, no retirement date announced |
| Care most about agentic terminal coding | Either — GPT-5.5 leads here per Anthropic's own footnote |
My short answer: yes, switch most things to 4.8. Run it for a week before you migrate anything where prompt-specific behaviour matters. The fact that 4.7 stays supported means there's no urgency on the long-tail of tuned tooling.
What I'd Do This Week
- Swap the model ID in your most-used tool first. Claude Code, your favourite agent, whatever you reach for daily. Run the same tasks you ran yesterday and notice what feels different. The honesty jump shows up fastest in real work, not synthetic evals.
- Set your effort level deliberately. The default is now
higheverywhere. For serious coding setxhighexplicitly; for cost-sensitive chat use the new effort control in claude.ai and dial down. Don't assume the default is tuned for your use case. - Check your billing after 48 hours. Listed price hasn't moved, but tokenizer and effort defaults can shift effective cost. Catch surprises before they're a monthly invoice.
- Don't rush dynamic workflows into production. It's a research preview. Try it on a real-but-non-critical migration first. Watch for runaway subagent costs.
- If you've automated against the API, test cache hit rates. The 1,024-token cache minimum may unlock savings on workflows that previously fell below the threshold.
- Keep an eye on refusal patterns. If 4.8 starts refusing legitimate work because of the safety-side tightening, log the examples and feed them back. The dev-community signal on this matters.
I'll update this article once I've put the new features through real work — particularly dynamic workflows on an actual migration, and the 4× honesty claim measured against a week's worth of my own agent runs. The benchmark table above also gets locked down the moment Anthropic publish the official system card. If you want the first look at that update, subscribe to the StationX newsletter or join my Circle community.
Claude Opus 4.8 FAQ
What is Claude Opus 4.8?
Claude Opus 4.8 is Anthropic's flagship coding and agentic model, released on 28 May 2026. It keeps Opus 4.7 pricing ($5 per million input tokens, $25 per million output), the 1M-token context window, and 128k max output. The headline change is honesty — Anthropic say it's 'around four times less likely than its predecessor to allow flaws in code it has written to pass unremarked.' It also adds dynamic workflows in Claude Code, user-facing effort control in claude.ai, a cheaper fast mode, and a lower 1,024-token prompt-cache minimum.
Is Claude Opus 4.8 free?
No. Same Opus pricing as 4.7 — $5 per million input tokens and $25 per million output. Pro and Max Claude Code subscriptions include it under existing fees. Fast mode is $10/$50 per million (about 3x cheaper than 4.7's fast mode and 2.5x faster). Anthropic cite one customer (Databricks Genie) seeing 61% cheaper token cost than 4.7 on a multimodal workload — that's a case study, not a blanket rate.
What are dynamic workflows in Opus 4.8?
Dynamic workflows is a Claude Code research preview where a single Opus 4.8 session plans a task, spawns hundreds of subagents in parallel to work on different parts, verifies their outputs, and adapts the plan as findings come in. It's designed for codebase-scale jobs like whole-repository migrations. It's gated to Claude Code — you can't trigger it from the raw API — and running hundreds of parallel subagents uses tokens fast, so it's overkill for small tasks.
What's the difference between Claude Opus 4.8 and 4.7?
4.8 is meaningfully more honest — Anthropic say it's 'around four times less likely than its predecessor to allow flaws in code it has written to pass unremarked' — and adds dynamic workflows in Claude Code, a cheaper fast mode (~3x cheaper, 2.5x faster), user-facing effort control in claude.ai, and a lower 1,024-token prompt-cache minimum. Coding and agentic benchmark scores are reported higher, but the exact figures await Anthropic's official system card. There are no breaking API changes — swap the model ID and your 4.7 code keeps working.
What is the default effort level on Opus 4.8?
The effort parameter defaults to 'high' on Claude Opus 4.8 across all surfaces, including the Claude API and Claude Code. If you set effort explicitly, your setting is left alone. For coding and high-autonomy work, Anthropic recommend setting 'xhigh' explicitly — it is not the default. The levels were also recalibrated versus 4.7: medium allows somewhat more thinking, high somewhat less, and xhigh substantially more, so re-baseline at the same level before adjusting.
Is Opus 4.7 being deprecated?
Not yet. Anthropic list claude-opus-4-7 as a legacy-but-available model with no published retirement date (the only Opus/Sonnet models retiring soon are the original Claude 4 pair, on 15 June 2026). If you've heavily tuned prompts, evals, or downstream tooling for 4.7-specific behaviour, you can stay on it without a forced cutover.
Does Opus 4.8 refuse legitimate work?
Sometimes. Launch-day developer feedback on Hacker News flags continued over-cautious behaviour — 'malware reminder' patterns triggering refusals on legitimate security code, shorter responses, and one reported bug causing a sharp spend increase on the same task. Anthropic's honesty gains are real, but the over-cautious refusal pattern is a known frustration. If you hit it on legitimate work, log the examples and report them.
Should I upgrade from Claude Opus 4.7 to 4.8?
For coding, agentic work, browser automation, and multimodal: yes, and there are no breaking API changes — swap the model ID and your 4.7 code keeps working. For heavily tuned 4.7 prompts and evals, you can stay on 4.7 (no retirement date announced). For agentic terminal coding specifically, GPT-5.5 still leads per Anthropic's own launch-post footnote (83.4% on Terminal-Bench 2.1).
About the Author

Nathan House, Founder & CEO of StationX
Nathan House has 30 years of hands-on cybersecurity experience and is Cambridge-educated, holding CISSP, CISA, CISM, OSCP, CEH, and SABSA. He founded StationX in 1999 — one of the UK’s first cybersecurity companies — and has secured £71 billion in UK mobile banking transactions and the London 2012 Olympics, advising clients including Microsoft, Cisco, BP, Vodafone, and VISA. He authored the world’s most popular cybersecurity course — a #1 Udemy bestseller taken by over 500,000 students — and was named Cyber Security Educator of the Year 2020, AI Security Educator of the Year, and a UK Top 25 Security Influencer 2025. A DEF CON speaker and featured expert on CNN, Fox News, NBC, and the BBC, Nathan leads StationX’s training of more than half a million students worldwide.
