Best Local LLM in July 2026 (Updated Monthly Methodology)

If you've gone looking for the best local LLM and ended up reading three "top 5 models for 2026" articles that contradict each other, you're not alone. The honest answer is that no listicle can keep up. Open-weight models ship weekly, leaderboards re-rank monthly, and half the benchmarks you'll see quoted in vendor blog posts no longer measure what they claim to.
So this article doesn't name a single "best" model. Instead, it gives you something that won't go stale: a method for finding the right local LLM for your use case, today and every month after. We'll cover how to read benchmarks honestly, the four sources serious practitioners actually monitor, the licence trap that costs companies real money, a brief note for security professionals on uncensored models, and a ten-minute check you can run on the first of every month.
I run Claude Opus 4.7 as my daily driver and fall back to local models for privacy-sensitive work and to keep my own students from being locked out by an API bill. The framework below is what I actually use. Let's get into it.
The Freshness Problem (Why This Article Isn't a "Top 5" List)
The reason best local LLM models lists go stale so fast isn't laziness — it's physics. In 2025 alone, the open-weight frontier moved from Llama 3 70B being a credible coding assistant to the Qwen 3 family matching mid-tier closed frontier performance. Then DeepSeek V3 broke the price-per-token curve. Then everyone re-released their flagships with reasoning modes. A "top 5" written in January is honest fiction by April.
The freshness problem isn't only about new releases either. The benchmarks themselves degrade. A test set leaks into training data. Vendors fine-tune on benchmark-shaped questions. A leaderboard's methodology becomes gameable, and within months the top of the ranking is dominated by models tuned to ace the test rather than the work. We'll come back to this in the section on reading benchmarks honestly.
So the lasting question isn't "which model is best right now". It's "how do I know what's best, today, for the work I'm doing". That's what the rest of this guide is for.

Start With Your Use Case, Not the Model
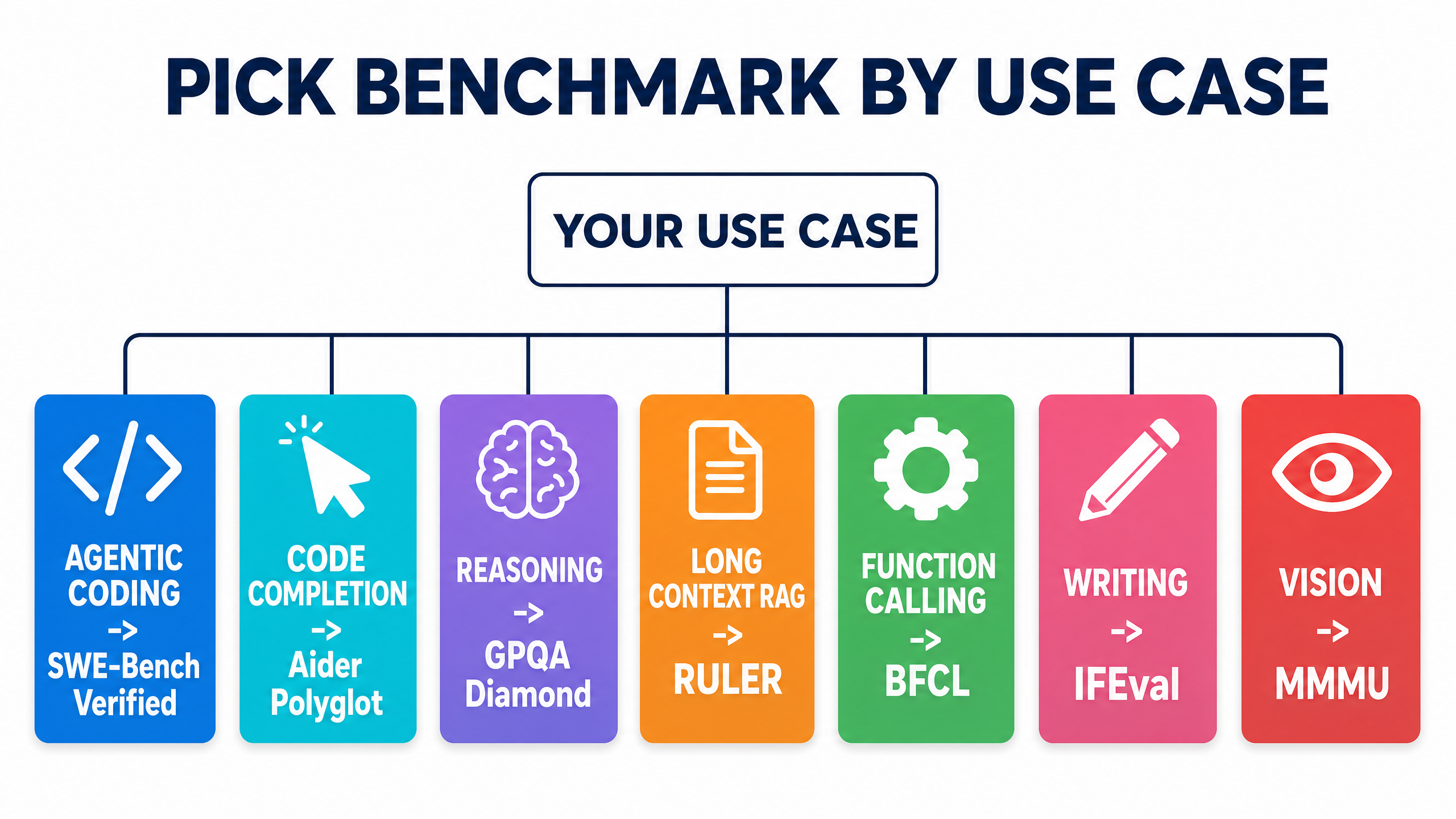
The single most common mistake — and I see it constantly with my students — is treating "best local LLM" as one question. It isn't. There are at least seven sub-questions hiding inside it, and the answer is different for each:
- Agentic coding (e.g. running through Aider or Claude Code with a local backend) — large reasoning matters more than raw token speed.
- Code completion and explanation — fast, small models that fit in your editor's context budget often beat bigger slower ones.
- General reasoning and study help — accuracy on multi-step problems, hallucination resistance.
- Long-context RAG (e.g. searching across documentation) — the actual usable context window, not the marketed one.
- Function calling and tool use — for agent workflows, browser automation, API orchestration.
- Writing and editing — the best local LLM for writing is judged on instruction-following, style preservation, and length control, not raw benchmark scores.
- Roleplay and red-team simulation — the best local LLM for roleplay needs to engage with adversarial scenarios without breaking character or refusing.
If you're picking the best local LLM for coding, the answer is genuinely different from the answer for long-context RAG. Decide what you're actually using the model for before you open a leaderboard. Otherwise you'll be misled by an overall ranking that averages across tasks you don't care about.
A quick test I give my students: write down the three tasks you'll use the model for this week. Not next quarter — this week. That's the use case you're optimising for.
The Benchmarks That Actually Predict Real-World Performance
Once you've named the use case, the next question is which local LLM benchmarks actually correlate with the work. This is where most articles go wrong. They cite whatever number the vendor put in the model card. The vendor cited it because it was flattering. You need to know which benchmarks are still informative and which are decorative.
Here's the use-case-to-benchmark map I actually use, all verified active as of May 2026:
| Use case | Benchmarks worth checking | Where they live |
|---|---|---|
| Agentic coding | SWE-Bench Verified, SWE-Bench Pro, Aider Polyglot | swebench.com, aider.chat |
| Code completion / short tasks | LiveCodeBench, BigCodeBench | livecodebench.github.io |
| Reasoning | GPQA Diamond, MMLU-Pro, MATH, AIME | artificialanalysis.ai, vellum.ai |
| Long context | RULER | github.com/NVIDIA/RULER |
| Function calling / tools | BFCL (Berkeley Function-Calling Leaderboard) | gorilla.cs.berkeley.edu |
| Multilingual | Flores, MGSM | artificialanalysis.ai |
| Vision | MMMU, MathVista | artificialanalysis.ai |
| Embeddings (for RAG) | MTEB | huggingface.co/spaces/mteb/leaderboard |
| Instruction following | IFEval, WildBench | livebench.ai |
A few benchmarks you'll see cited that are now functionally dead: HellaSwag, bare HumanEval, and naïve Needle-in-a-Haystack long-context tests. All three are saturated, contaminated, or both. If a vendor's headline number is HumanEval, they're picking the friendliest reading they can find. Look at LiveCodeBench or BigCodeBench instead. RULER replaced Needle-in-a-Haystack for honest long-context evaluation in 2024 — anyone still quoting "1M context, 99% on NIAH" in 2026 is selling you something.

The single highest-signal coding score is SWE-Bench Verified for agentic work and Aider Polyglot for editor-style code generation. They're contamination-resistant because the test sets are refreshed and the tasks involve real GitHub issues, not toy problems.
The 4 Sources Every Serious Practitioner Monitors
Here's the toolkit. Four sources, ranked by signal-to-noise. Together they take about ten minutes to skim once a month, which is the maintenance budget I think is reasonable for someone who actually wants to keep up.

1. LMSYS Chatbot Arena (lmarena.ai) — Human Preference
Real users blind-test models head-to-head and vote on the winner. The result is an Elo score that captures something benchmarks can't: how a model actually feels to use. It's noisy at the top (Elo is sensitive to who's voting that week) but excellent for spotting genuine shifts in capability. Filter to "open" models to see the local-runnable picture.
Best for: sanity-checking benchmark claims, catching new releases that are actually good versus paper-good.
2. The Capability Triad — LiveBench, Aider Polyglot, SWE-Bench Verified
These three are the contamination-resistant capability benchmarks. LiveBench refreshes tasks monthly so models can't be pre-trained on the test. Aider Polyglot tests editor-style coding across languages. SWE-Bench Verified is the gold standard for agentic coding. Take a top-5 from each, look for models that appear in all three.
If a model crushes one benchmark and is missing from the others, that's a tell. It's been optimised for the visible scoreboard. The triad rewards genuine capability.
3. r/LocalLLaMA — The Best Local LLM Reddit Answer
The community that actually runs these models on real hardware. You will learn things here that benchmarks can't tell you: which models break at certain quantisation levels, which ones are unusable on Apple Silicon, which "small enough to run locally" claims are honest and which require a server farm. The signal-to-noise is higher than any other forum I'm aware of for this topic.
Skim the weekly "best models" megathreads. Search for your specific hardware. The community is opinionated, sometimes wrong, but always informed.
4. Your Own 20-Prompt Private Eval
This is the only ungameable source. Pick 20 prompts you actually use — five from your real work, five edge cases, five "easy" prompts that should always pass, five from your last failure mode. Save them in a text file. Run them against any model you're considering, side by side with your current default. Score them yourself.
I will say this directly: I trust the output of a 20-prompt private eval more than any leaderboard. The ten minutes it takes is the single highest-leverage piece of LLM evaluation work you can do.
Honourable mentions worth knowing: Artificial Analysis (artificialanalysis.ai) for price-and-speed comparisons across hosted endpoints; MTEB for embeddings specifically; BFCL for function calling specifically; Vellum and Onyx as current open-weight aggregators. Use these when you're going deep on one dimension — the four sources above are the monthly skim. Onyx in particular runs the best self-hosted AI model leaderboard if you want a self-hosted-only view.
How to Read Benchmarks Honestly (and Which Ones Are Dead)
A few rules I'd hand to anyone evaluating models, especially my students:
Vendor benchmarks are marketing. If the only source for a claim is the vendor's blog post, treat it as marketing until corroborated by an independent leaderboard. This applies to closed and open-source models equally.
Contamination is endemic. If a benchmark has been around for more than 18 months, assume some training data overlap with the test set. This is why LiveBench's monthly refresh, and SWE-Bench Verified's curated approach, matter so much.
Benchmaxxing is real. "Benchmaxxing" is the practice of fine-tuning a model to maximise a specific benchmark's score, often at the cost of general capability. You spot it by looking for the gap between a model's benchmark score and its LMSYS Arena rank. A wide gap, especially with the model scoring well on a contamination-prone benchmark, is a tell.
The HuggingFace OpenLLM Leaderboard is no longer authoritative. Both v1 and v2 have been retired. If a source you're reading still treats it as current in 2026, the source is out of date. Vellum, Onyx, and Artificial Analysis now fill that aggregator gap.
Why leaderboards diverge: different benchmarks measure different things, weight them differently, and have different contamination profiles. A model topping one leaderboard and ranking mid-tier on another usually means the truth is somewhere in the middle. Triangulate, don't rely on one source.
The Licence Trap — Open-Weight ≠ Commercial-OK
This is the section that has saved me from more than one expensive mistake.
Open-weight does not mean commercial-use is permitted. It means the weights are downloadable. The licence is a separate question, and several of the most popular "open-source" models have restrictions that bite hard when you try to use them in a product.
Examples to be aware of:
- MiniMax models ship with restrictions on competitive use and certain commercial deployments.
- Llama 4 uses a custom community licence with a monthly active user cap (700M) — fine for most, but check.
- Modified-MIT licences are increasingly common and may include attribution or use restrictions that standard MIT does not.
- Cohere Command-R+ is non-commercial weights only — the API is a different licence.

The 60-second check that saves you a legal review later:
- Open the model's HuggingFace page.
- Find the licence field.
- Read the licence file itself — not the model card's summary.
- Look specifically for use restrictions (commercial, military, competitive), attribution requirements, and acceptable use clauses.
- If you're deploying in a product, get a lawyer to confirm. If you're using it for personal work or study, you're almost certainly fine, but check anyway.
The cost of getting this wrong is being asked to remove a model from production after launch. The cost of checking is one minute.
The Uncensored Question — a Note for Security Professionals
A practical note for those in cybersecurity, which is where most of my students sit. Aligned models — Claude, GPT, Llama-Instruct, Qwen-Instruct — refuse a lot of work that is entirely legitimate. Explaining a published CVE. Walking through how a known piece of malware behaves. Generating red-team prompt variations for awareness training. Writing realistic phishing samples to test a defence pipeline. All routinely refused by the major aligned models, and all routinely required by security professionals working in authorised scope.
This is what the uncensored or abliterated local LLM ecosystem exists to address. A small group of maintainers produce derestricted versions of mainstream models — the four I'd point you at are Eric Hartford's Dolphin series, mradermacher, TheDrummer, and mlabonne. Two techniques dominate: abliteration (directional ablation of the refusal vector) and DPO refusal-removal (less invasive, often preserves capability better). The frontier approach combines both — abliteration followed by DPO to recover capability lost in the ablation.
The UGI Leaderboard (huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard) tracks how "willing" different models are. Treat it as directional, not authoritative — it's run by one person as a HuggingFace Space and the maintainer explicitly says the scores are "for reference only". But it's the best public signal we have.
Two things to be honest about. First, uncensoring usually degrades capability — the post-ablation model often loses some reasoning quality, and "abliterated" labels are unreliable marketing. Second, the model not editorialising isn't a licence to generate anything; the professional ethic — authorised scope, sandbox environment, defensive intent — sits upstream of model choice and doesn't change because the refusal layer is gone.
If you're a student doing red-team or CVE work and finding the major models refuse legitimate questions, the uncensored ecosystem is a real tool and worth knowing about. Use it the way you'd use any other dual-use tool in our field.
The 10-Minute Monthly Check (the Repeatable Process)
Here's the process I run on the first of each month. It takes about ten minutes once you've done it twice.
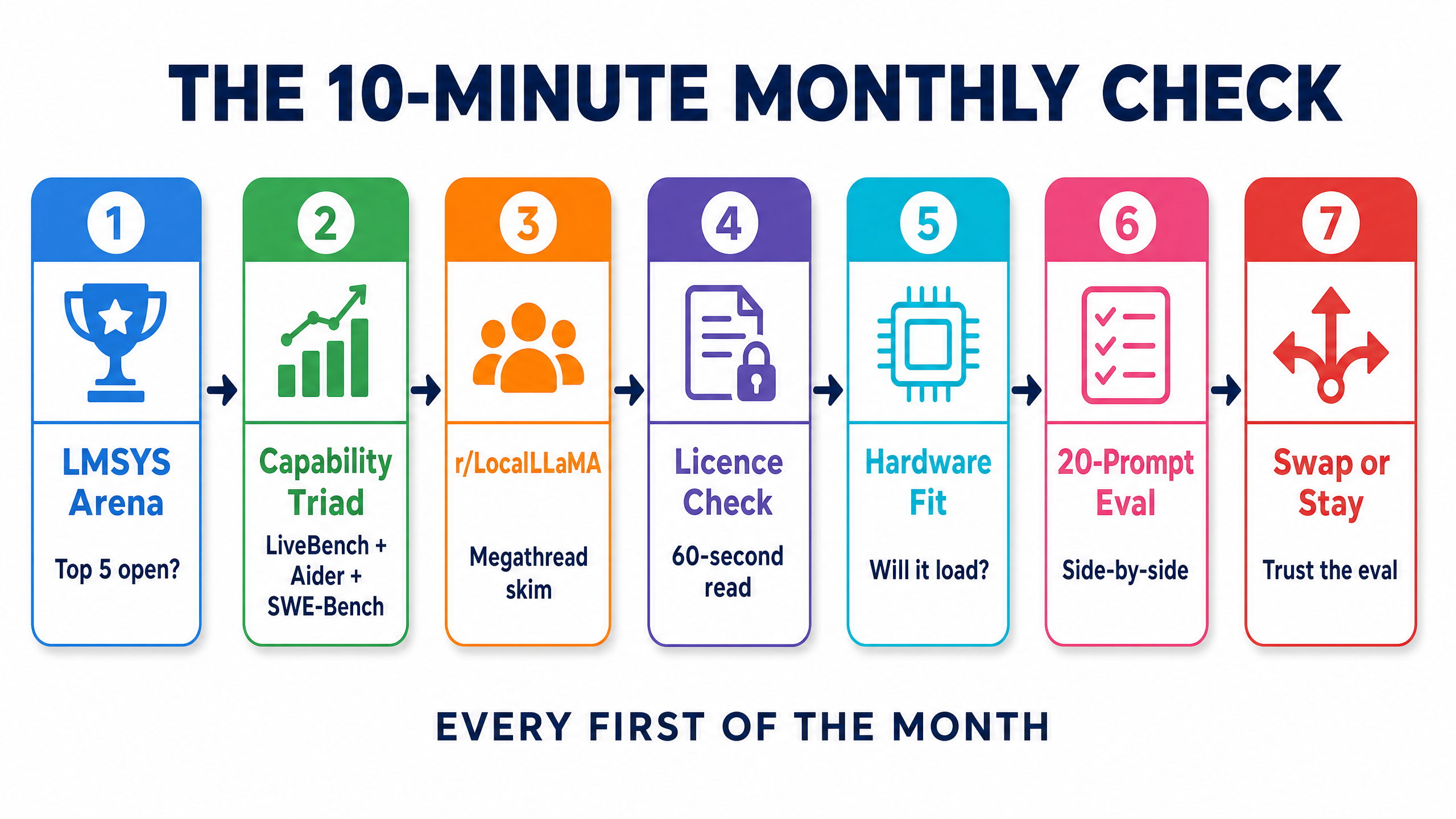
- Open LMSYS Arena (lmarena.ai). Filter to open models. Note the top 5. Has the order shifted? Any new entrants?
- Check the capability triad — LiveBench, Aider Polyglot leaderboard, SWE-Bench Verified. Note the top open-weight in each.
- Skim r/LocalLLaMA for the weekly "best of" megathread. What are people actually running? What's broken?
- Verify licence for any new candidate you're tempted by. Sixty-second check, as above.
- Verify hardware fit. The best benchmarks in the world don't matter if it won't load on your machine.
- Run your 20-prompt eval against the candidate, side by side with your current default. Score yourself.
- Swap or stay. If the new candidate genuinely outperforms on your eval, swap. If not, stay. Don't chase noise.
That's it. Ten minutes a month keeps you honest, evidence-based, and free from listicle theatre.
What Never Changes (Principles That Survive Every Release)
A few principles that don't go out of date no matter how fast the models do.
Use case first, model second. The best general model is rarely the best for your specific work.
Licence first, capability second. Building on a model you can't ship is wasted effort.
Contamination-resistant benchmarks beat saturated ones. SWE-Bench Verified over HumanEval. LiveBench over MMLU. RULER over Needle-in-a-Haystack.
Your own 20 prompts beat any leaderboard. Always. Run them.
Hybrid is fine. You don't have to pick. Many of my students — and I do this too — run a frontier closed model (Claude, GPT) for hard problems and a local model for routine, privacy-sensitive, or high-volume work. The right answer is often "both".
So what is the best local LLM? The honest answer: the one that wins your 20-prompt eval, ships under a licence you can use, and fits the hardware you actually own. Everything else is decoration. That's true for the best open source local LLM just as much as for the best local coding LLM.
If you don't yet have a local model running, our Claude Code with Ollama guide walks you through the setup end-to-end with current hardware tiers and a working default. This methodology article and that setup guide are designed as a pair — one tells you how to choose, the other tells you how to run.
❓ Best Local LLM FAQ
What is the best local LLM right now?
The honest answer is: it depends on your use case, your hardware, and what you're willing to spend ten minutes evaluating. There is no single best local LLM — there's the best for your work, this month. Use the 4-source toolkit (LMSYS Arena, the capability triad of LiveBench + Aider Polyglot + SWE-Bench Verified, r/LocalLLaMA, and your own 20-prompt eval) to find it.
What's the best local LLM for coding?
For agentic coding (Aider, Claude Code with a local backend), check the top of SWE-Bench Verified for open-weight entries. For code completion and editor use, the Aider Polyglot leaderboard is more relevant. Both lists move month to month — check live, don't trust a static article.
Are open-source LLMs as good as ChatGPT or Claude?
For routine work, surprisingly yes. For genuinely hard agentic coding and complex reasoning, the closed frontier (Claude Opus, GPT, Gemini) is still ahead on SWE-Bench Verified by a meaningful margin. The gap has narrowed every quarter for two years and is unlikely to widen. For privacy-sensitive work, the right open-weight model is genuinely competitive.
Where do I find new local LLMs?
The 4-source toolkit: LMSYS Chatbot Arena for human preference, the capability triad (LiveBench, Aider Polyglot, SWE-Bench Verified) for contamination-resistant evaluation, r/LocalLLaMA for hardware reality, and your own 20-prompt private eval. Plus Artificial Analysis for price-and-speed comparisons, MTEB for embeddings, BFCL for function calling, and Vellum or Onyx as current open-weight aggregators.
What hardware do I need to run a local LLM?
That depends on which model and at what quantisation. The short version: 8GB VRAM runs small models at low quality, 16GB runs useful 7-13B models at good quality, 24GB+ runs the larger open-weight models comfortably, and Apple Silicon's unified memory is excellent for inference. The full hardware breakdown sits in our Claude Code with Ollama guide.
Is it legal to use an uncensored LLM?
Generally yes, with two caveats. First, the model's own licence still applies — check it. Second, what you generate with it is your responsibility, regardless of whether the model refused or not. The professional ethic — authorised scope, defensive intent, sandbox environment for sensitive work — applies the same way it applies to any other dual-use security tool.
If you found this useful, you might also like our Claude Code with Ollama guide — covers the hardware and setup so you can actually run whichever model the framework above points you at.
Last verified: 18 May 2026. The methodology here is built to outlast specific model picks — the leaderboards and communities above are the source of truth, not this article.
About the Author

Nathan House, Founder & CEO of StationX
Nathan House has 30 years of hands-on cybersecurity experience and is Cambridge-educated, holding CISSP, CISA, CISM, OSCP, CEH, and SABSA. He founded StationX in 1999 — one of the UK’s first cybersecurity companies — and has secured £71 billion in UK mobile banking transactions and the London 2012 Olympics, advising clients including Microsoft, Cisco, BP, Vodafone, and VISA. He authored the world’s most popular cybersecurity course — a #1 Udemy bestseller taken by over 500,000 students — and was named Cyber Security Educator of the Year 2020, AI Security Educator of the Year, and a UK Top 25 Security Influencer 2025. A DEF CON speaker and featured expert on CNN, Fox News, NBC, and the BBC, Nathan leads StationX’s training of more than half a million students worldwide.
