LLM Limitations: Why the Flaws Won't Stop Adoption

One of the people who helped invent modern AI has just quit one of the world's best-funded AI operations to prove it's heading down a dead end. Yann LeCun — Turing Award winner, the man whose work on convolutional neural networks powered a generation of modern computer vision — is leaving Meta to build an alternative to the text-first LLM paradigm entirely. That's not a hot take from the sidelines. That's a founder of the field betting his next chapter against the very thing everyone else is pouring billions into.
So it's worth taking his argument seriously. LeCun has a specific, technical list of LLM limitations he thinks are fatal — and if you've used these tools for real work, you've felt every one of them. We'll go through that list honestly, then hear the experts who think he's wrong, and look at his proposed alternative.
But I'm going to end somewhere uncomfortable for both camps. Because here's my honest view after running a real business on this technology: LeCun is right about the flaws — and it mostly doesn't matter. Let me show you why.
Why a Founder of AI Is Betting Against LLMs
To understand why this matters, you have to know who's saying it. Yann LeCun isn't an outsider lobbing criticism. In the 1980s and 90s he pioneered the convolutional neural networks that power modern image recognition. In 2018 he shared the Turing Award — computing's Nobel — with Geoffrey Hinton and Yoshua Bengio, the three so-called godfathers of deep learning. He built and ran Meta's FAIR research lab and became its Chief AI Scientist.
In late 2025 he announced he was leaving Meta to start his own venture, dedicated to a different kind of AI: systems that, in his words, "understand the physical world, have persistent memory, can reason, and can plan complex action sequences." Read that list again — it's a point-by-point inventory of what he thinks today's LLMs can't do. The reported friction was Meta's pivot toward ever-larger commercial language models, exactly the paradigm he's arguing against.
When someone with that record walks away from the world's best-funded LLM operation to do the opposite, the polite thing is to actually hear the argument out.

The 5 LLM Limitations Critics Say Are Fatal
Here are the core limitations of LLMs that LeCun and other critics keep returning to. I've kept them in plain English, because each one maps onto something you've probably hit yourself.
1. No understanding of the physical world. Language describes reality; it isn't reality. Train a model only on text and it learns a description of the world — a shadow of it — not the thing casting the shadow. That's why a model can write a flawless essay on gravity and still fail at the intuitive physics a toddler has mastered. As Richard Sutton, a Turing Award winner and the father of reinforcement learning, put it bluntly on the Dwarkesh podcast in 2025: "Large language models are about mimicking people, doing what people say you should do. They're not about figuring out what to do."
2. They can't truly reason. What looks like reasoning in "thinking" models is, to LeCun, closer to search: the system generates many candidate paths and a scoring step picks the most plausible-looking one. In a 2025 Newsweek interview he was direct about it: "An LLM produces one token after another… that's clearly System 1 — it's reactive, right? There's no reasoning." ("System 1," from psychologist Daniel Kahneman, is the fast, automatic kind of thinking — as opposed to slow, deliberate "System 2" reasoning.)
3. Hallucinations aren't fully fixable. When a model has no ground truth for something, it fills the gap with statistically plausible fiction — confident, fluent, and wrong. Critics argue this is a structural feature of next-token prediction, not a bug you can train away with more data or more human feedback. You can reduce it. The claim is that you can't eliminate it, because the mechanism that makes the model fluent is the same one that makes it make things up.
4. They can't plan over long horizons. A teenager learns to drive competently from a few dozen hours behind the wheel. We've spent billions and still don't have reliable level-five self-driving. To critics, that gap is a tell: the underlying approach doesn't connect to how the physical world actually works, so it struggles with the multi-step, consequence-aware planning that real-world tasks demand.
5. Scaling is hitting a wall. The industry ran the experiment — more parameters, more compute, more data, more human feedback, added reasoning layers. The benchmark gains keep coming, but they're getting smaller relative to the cost. LeCun and Sutton read this as a structural ceiling, not a temporary plateau.
The honest version
Every one of these is at least partly true. If you've watched an LLM confidently invent a citation, lose the thread of a long task, or "reason" its way to a wrong answer, you've met these limitations in person. The disagreement isn't whether the flaws exist. It's whether they're permanent.
The Other Side: Why Plenty of Experts Think He's Wrong
Here's where I have to be fair, because this is genuinely contested — and some of the people on the other side are every bit as credentialed as LeCun.
Start with one of his fellow godfathers. Geoffrey Hinton — who shared that same 2018 Turing Award — doesn't see these models as shallow mimics at all. He's argued that large language models were born from a theory of how the brain processes language, and that they may work in much the same way we do: "They're the best theory we've currently got of how the brain understands language… we think probably they work in fairly similar ways." If Hinton is right, the "it's just predicting text" dismissal misses what's actually going on under the hood.
Then there's the moderate middle. Andrej Karpathy — a founding figure at OpenAI and former head of AI at Tesla — pushed back on the hype and the doom in the same breath on the Dwarkesh podcast in late 2025. His framing: "there's some over-prediction going on in the industry. In my mind, this is more accurately described as the decade of agents." Not a dead end. Not next year, either. A decade of hard, real engineering — which is a very different claim from "structurally impossible."
And on hallucinations, even the people building these systems agree they're a real problem — they just treat it as something to engineer around, not a wall. Sam Altman, OpenAI's CEO, said it plainly on his own podcast in 2025: "People have a very high degree of trust in ChatGPT, which is interesting, because AI hallucinates. It should be the tech that you don't trust that much." Coming from the person with the most to gain from overselling it, that's a notably honest admission — and an engineering mindset, not a surrender.
| Voice | Position on LLM limitations |
|---|---|
| Yann LeCun | Structural ceilings — text alone can't reach human-level AI. Build world models instead. |
| Richard Sutton | LLMs mimic people rather than learn from experience — a dead end for real intelligence. |
| Andrej Karpathy | Real but early. Not a dead end — a "decade of agents" of hard engineering ahead. |
| Geoffrey Hinton | These models may understand language much as the brain does — far less shallow than critics claim. |
| Sam Altman | Hallucination is real and the tech is over-trusted — but it's an engineering problem to solve. |
So this isn't settled science with one heretic. It's a genuine split among the people who built the field. Which is exactly why I think arguing about who's ultimately right is the wrong question for almost everyone reading this.
World Models and JEPA: LeCun's Alternative
If LLMs are the off-ramp, what's the road? LeCun's answer is the world model, and his specific architecture for it is called JEPA — Joint Embedding Predictive Architecture.
The idea is to flip what the model predicts. An LLM predicts the next word. A pixel-level video model predicts the next frame, which is hopelessly expensive and detail-obsessed. JEPA predicts the next state at a higher level of abstraction — it learns to anticipate what happens next in terms of objects and interactions, not exact words or pixels. The bet is that a system trained this way builds an internal model of how the world works, which is what lets animals and humans plan, reason about consequences, and learn a new task from a handful of examples instead of an internet's worth of text.
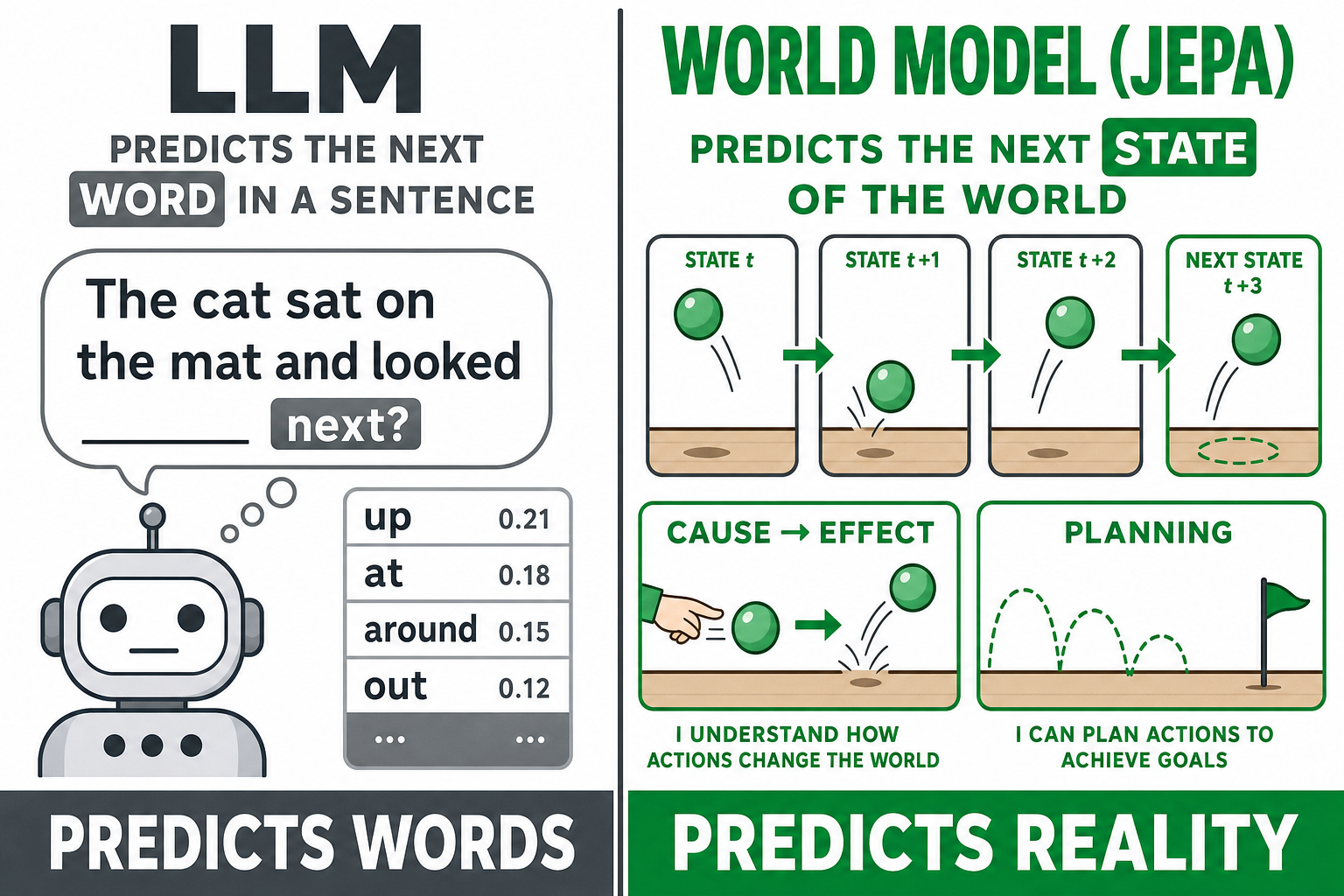
It's a serious idea from a serious researcher, and early versions exist. But two honest caveats matter. First, it's early — this is a research direction, not a shipping product, and by LeCun's own framing a real payoff is years out. Second, the "the whole industry is asleep on this" framing oversells the gap: the major labs are already folding world-model and planning research into their stacks rather than betting everything on bigger text models. You can't ship a research dream, which is precisely why the same labs keep funding LLMs in the meantime. That tension — promising future versus useful present — is the whole story, and it's where my own view comes in.
My Take: Flaky Doesn't Mean Useless — and the Economics Decide
Here's where I'll plant my flag, because I'm not watching this from a lab — I'm running a business on this technology every day.
LeCun is right. LLMs are flaky. Left to their own devices they hallucinate, lose the plot on long tasks, and produce confident nonsense. I'm not going to pretend otherwise; I've seen all of it. But "flaky" is the wrong test, and it's the test the entire dead-end debate keeps failing. The real question isn't "is the raw model reliable?" It's "is the model, wrapped in a good system, good enough?" — and the answer is plainly yes.
The point everyone misses
A flaky model inside a good system is not a flaky system. Guardrails, retrieval, verification loops, and a human at the right checkpoint turn an unreliable model into a reliable workflow. At StationX, LLMs wrapped in exactly that kind of system already run roughly 80% of how we operate. Not as a demo — as the actual business.
That word — system — is the whole game. The skill that matters in 2026 isn't owning a perfect model; it's being the person who can build the scaffolding around an imperfect one so its output is safe to rely on. That's a craft, and it's a defensible one. The model is a commodity. The system is not.
And now the part that makes all of this academic, in the precise sense of the word. Even if the model is only "good enough," the economics make adoption unavoidable. This is the most important thing in the whole article, so let me be exact about it.
Look at what's already happened. McKinsey's 2025 State of AI survey found that 88% of organisations now use AI in at least one business function, up from 78% a year earlier — near-universal adoption. And here's the kicker from the same study: only 39% report any AI-attributable impact on profit at the enterprise level, and most of those say it's under 5% of EBIT. Sit with that. Almost everyone has adopted AI. Almost no one can yet prove it's making them money.
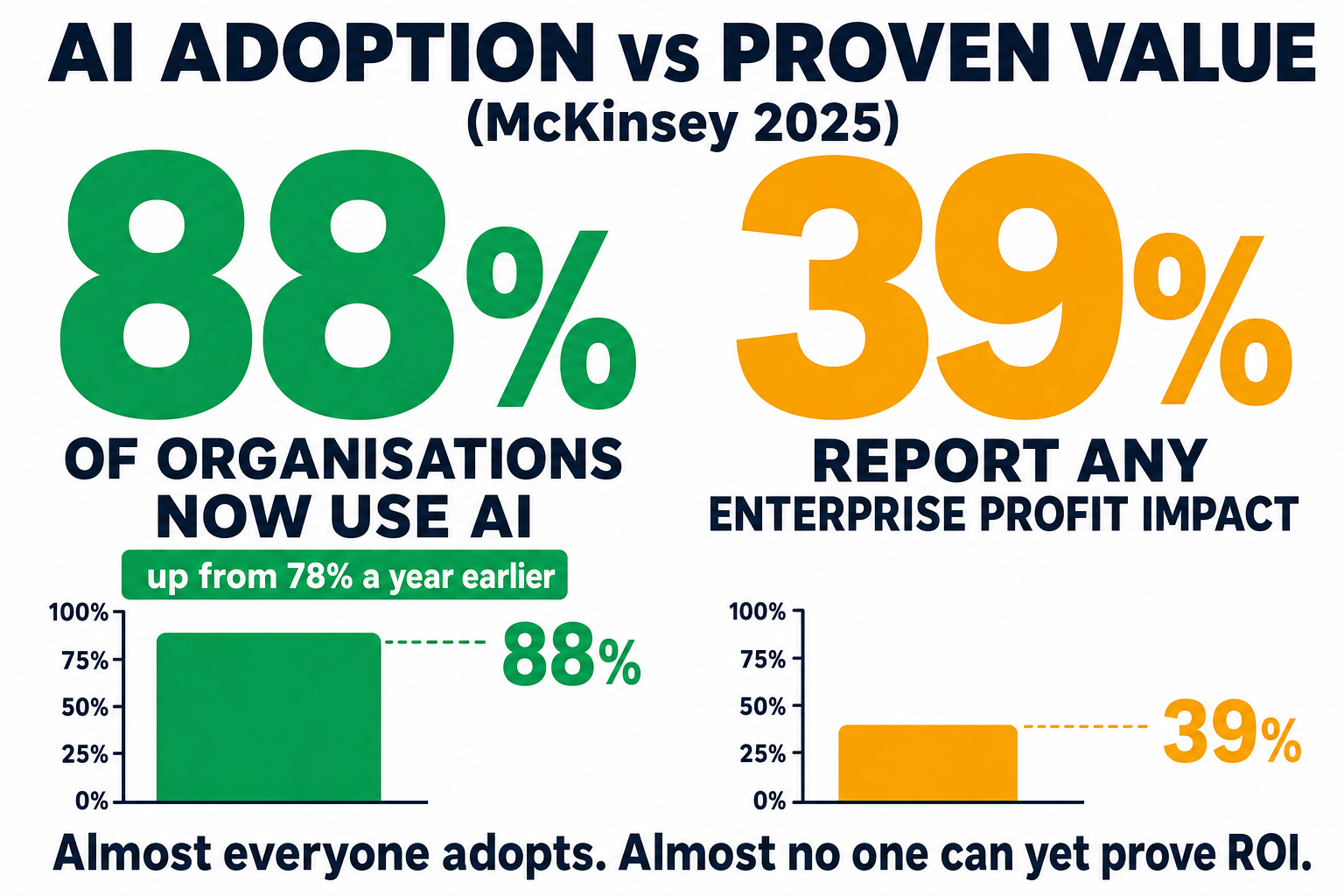
Now, I have to separate two things here, because the honest objection to my own argument lives in the gap between them. There's adoption — everyone switching it on — and there's advantage — it actually making a firm faster or cheaper. The 39% figure could mean the whole thing is a hype bubble that corrects, with the flaws eventually stopping adoption after all. That's a fair reading, and I won't wave it away. But it isn't the one I see, and the reason is that the advantage is real at the workflow level even while it's invisible at the enterprise-EBIT level. A SOC analyst triaging alerts with an AI assist, a support team clearing tickets, a marketing team producing ten times the content, a developer shipping faster with AI review — those gains are concrete and measurable, even when they're too diffuse to show up as a clean line on the group P&L yet. The value is there; the accounting just hasn't caught up.
And that's exactly why the flaws don't stop adoption. Companies aren't adopting AI because the enterprise ROI is proven or the technology is flawless. They're adopting it because the moment a competitor gets those workflow-level gains, matching their speed and cost stops being a choice — it becomes the price of staying in the game. This is a classic competitive trap: the technology doesn't have to be good in any absolute sense — it only has to be good enough that the firms using it out-pace the firms that don't. Once that's true, everyone is pulled in, perfect or not.
So LeCun can be completely correct that LLMs are an off-ramp on the road to human-level intelligence, and it changes nothing about your next three years. He's arguing about the destination. Businesses live on the near horizon — and on that horizon, "good enough and economically forced" beats "theoretically a dead end" almost every time.
What This Means for Your Career
If you take one thing from all this, make it this: don't spend your energy betting on who wins the LeCun-versus-the-scalers argument. You don't need to. The near-term outcome is the same either way — these tools get adopted everywhere, flaws and all.
The career move follows directly. Don't aim to be the person who has the best model; you'll never own that. Aim to be the person who can build the system around the model — the guardrails, the verification, the human-in-the-loop checkpoints that turn a flaky model into trustworthy work. For people in cybersecurity especially, that's home turf: verifying outputs you can't fully trust, assuming the thing in front of you might be wrong or compromised, and proving it's safe before you sign your name to it. That discipline is about to be worth a great deal.
One concrete first step: take a piece of AI output you'd normally just accept — a script it triaged, a summary, a chunk of code — and instead of using it, build a small verification loop that proves it's correct and safe before you'd rely on it. That habit, repeated, is the skill the next decade pays for. The model will stay flaky. Your job is to make the system around it solid.
The Bottom Line
The LLM limitations are real. LeCun, Sutton and others have named them honestly, and if you've done serious work with these tools you've felt every one. Whether they're permanent ceilings or solvable engineering problems is a genuine fight between brilliant people, and I won't pretend it's resolved.
But for almost everyone who isn't running a frontier lab, that fight is the wrong thing to watch. A flaky model inside a good system is good enough to do real work — it already runs most of mine. And once the economics tip, adoption stops being a verdict on the technology and becomes the cost of competing. So don't wait for the model to get perfect, and don't bet your career on it failing. Learn to build the system around it. That's where the value is — and that's the bet I'd make.
LLM Limitations FAQ: Your Questions Answered
What are the main limitations of LLMs?
Critics point to five: no grounded understanding of the physical world (they learn from text, not reality), no genuine reasoning (chain-of-thought is closer to search than thought), hallucinations that reduce but never fully disappear, weak long-horizon planning, and diminishing returns from scaling. These are real. The open question is whether they are permanent ceilings or engineering problems being chipped away.
Does Yann LeCun think LLMs are a dead end?
Effectively, yes — as a route to human-level intelligence. LeCun argues you cannot reach human-level AI by training on text alone, calling LLM output 'reactive' with 'no reasoning,' and he left Meta to build an alternative based on world models. He does not claim LLMs are useless today; he claims they are an off-ramp, not the road to general intelligence.
If LLMs are flawed, why are companies adopting them so fast?
Because adoption is an economic decision, not a verdict on whether the technology is perfect. McKinsey found 88% of organisations now use AI in at least one function (up from 78% a year earlier), even though only 39% report any enterprise-level profit impact yet. Once competitors run on AI, matching their speed and cost stops being optional — the economics make adoption close to unavoidable, flaws and all.
Are LLMs good enough to run a real business?
In our experience, yes — when you wrap them in a system. On their own they are flaky. Inside a system with guardrails, retrieval, verification and a human in the loop, they are reliable enough to handle a large share of real operational work. The skill that matters is not the raw model; it is the system built around it.
What is a world model, and how is it different from an LLM?
A world model learns how the world behaves — objects, physics, cause and effect — so it can predict and plan, the way animals and humans do. An LLM predicts the next token in text. LeCun's JEPA (Joint Embedding Predictive Architecture) is a world-model approach that predicts abstract representations of future states rather than words or pixels. It is early-stage research, years from production.
Will scaling LLMs lead to AGI?
That is the central dispute. LeCun and Richard Sutton argue scaling is hitting a structural wall. Others, including Geoffrey Hinton, see far more capability in these systems and treat the limits as solvable. The honest position in 2026 is that nobody has settled it — and for most businesses, it does not change the near-term decision to adopt.
About the Author

Nathan House, Founder & CEO of StationX
Nathan House has 30 years of hands-on cybersecurity experience and is Cambridge-educated, holding CISSP, CISA, CISM, OSCP, CEH, and SABSA. He founded StationX in 1999 — one of the UK’s first cybersecurity companies — and has secured £71 billion in UK mobile banking transactions and the London 2012 Olympics, advising clients including Microsoft, Cisco, BP, Vodafone, and VISA. He authored the world’s most popular cybersecurity course — a #1 Udemy bestseller taken by over 500,000 students — and was named Cyber Security Educator of the Year 2020, AI Security Educator of the Year, and a UK Top 25 Security Influencer 2025. A DEF CON speaker and featured expert on CNN, Fox News, NBC, and the BBC, Nathan leads StationX’s training of more than half a million students worldwide.
