Claude Opus 4.7 Review: Everything New in 2026

Anthropic released Claude Opus 4.7 on 15 April 2026, and if you use Claude Code for any real work, a lot has changed underneath you. New commands, a new default effort level, breaking API changes, and a real trade-off on long-context recall that nobody's talking about. Most of us are on Pro or Max subscriptions — not paying per token — so the bill-shock story is different from what you'll read elsewhere. But your usage limits will get hit faster, and that's where this actually matters.
I've spent the past few days reading the model card, digging through the Claude Code binary on my own Mac, and trying the new features on a real project. This is what I've found, what I think you should actually do with it, and the parts I can't test yet.
Here's the structure. First, what shipped. Then the four new things worth your attention — /ultrareview, xhigh, auto mode, and /ultraplan. Then the under-the-hood changes, and what I'd do this week.
What Actually Shipped on 15 April
The headline: Opus 4.7 is a coding and agentic model upgrade. Anthropic didn't touch the price, but most of the benchmark gains are where developers spend their time.
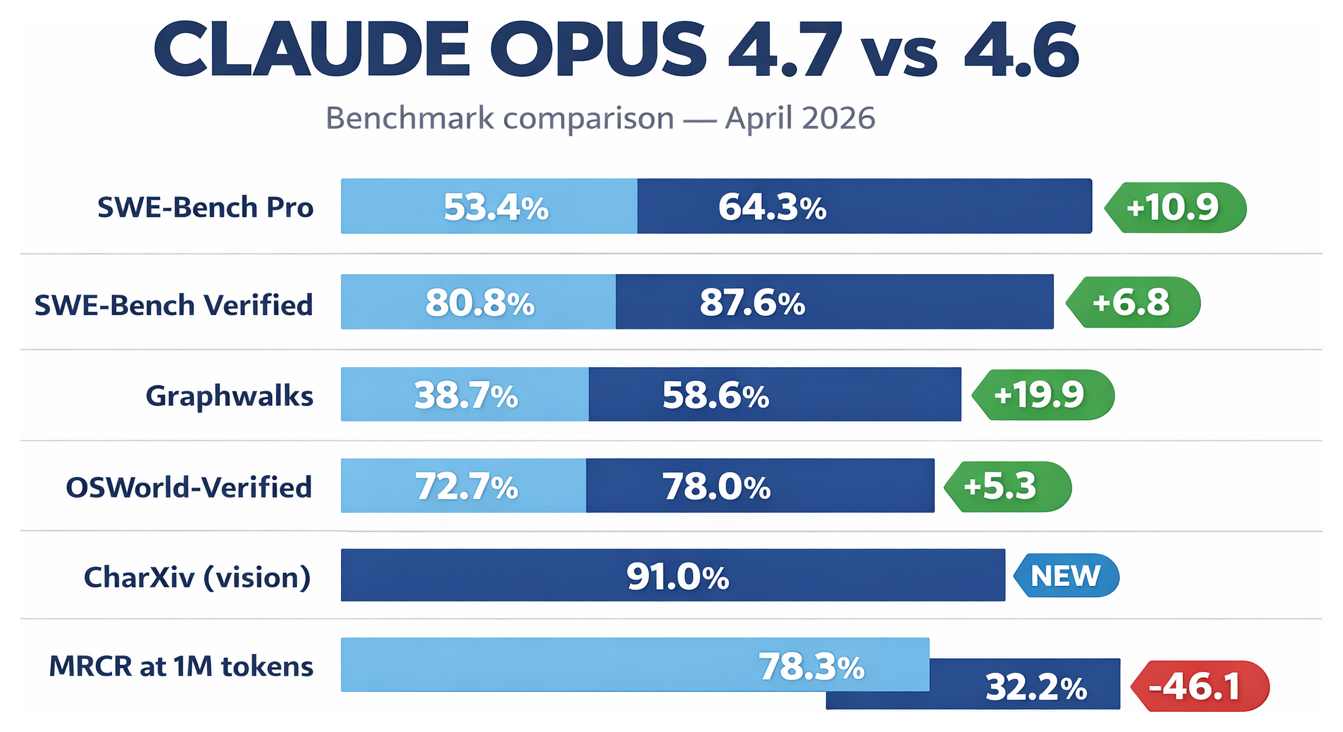
| Benchmark | Opus 4.6 | Opus 4.7 | Change |
|---|---|---|---|
| SWE-Bench Pro | 53.4% | 64.3% | +10.9 |
| SWE-Bench Verified | 80.8% | 87.6% | +6.8 |
| Graphwalks (multi-hop reasoning) | 38.7% | 58.6% | +19.9 |
| OSWorld-Verified (computer use) | 72.7% | 78.0% | +5.3 |
| CharXiv (vision, with tools) | — | 91.0% | — |
| MRCR at 1M tokens (recall) | 78.3% | 32.2% | −46.1 |
Source: Anthropic model card and whats-new doc.
That last row isn't a typo. Long-context recall at the extreme end of the window got meaningfully worse. We'll come back to it.
What you'll notice more day-to-day is the four new features below, because they change how you use Claude Code, not just how well the model scores on evals.

/ultrareview: A Cloud-Based Code Reviewer
Anthropic describes /ultrareview as a "dedicated review session that reads through changes and flags bugs and design issues that a careful reviewer would catch." You run it from Claude Code, it spins up a separate session on Anthropic's cloud, and a multi-agent reviewer works through your diff for 10-20 minutes.
It costs roughly $10-20 per run beyond the free allowance. Pro and Max users get three free runs as a trial — not a monthly refresh, a one-time try.
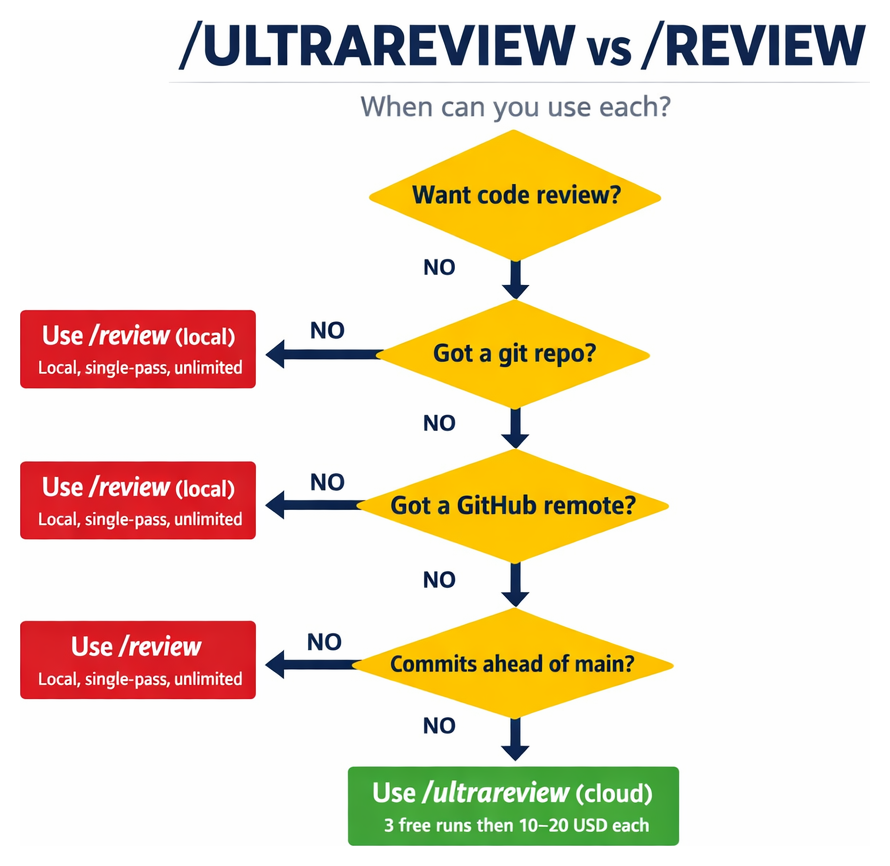
Here's the catch that isn't in the marketing: you can't point it at existing code. Three things have to be true before it will launch:
- A git repository.
- A GitHub remote (not GitLab, not local-only).
- Commits ahead of
main— or a PR number you pass explicitly.
If any of those are missing, it refuses. That's fine if you're using it the way Anthropic intends — as a pre-merge check on a pull request. But a lot of people's first instinct is to point it at a codebase they inherited, or an old project they want audited. It won't do that. For those cases, use /review, which is the local single-pass equivalent baked into Claude Code — no cloud, no GitHub, works on any diff.
Debugging AI tools — a real example
Part of working with AI-driven tools is learning to debug when the error messages are useless. I hit this one trying /ultrareview on a 1.7 GB repo — it bounced with a generic "failed to launch the remote session" and nothing more.
Digging into the Claude Code binary surfaced the real cause — "Repo is too large to bundle" — buried in the source strings but hidden from users. Lesson for anyone getting into AI engineering: when an agentic tool fails without explanation, the answer is often in the binary or the logs, not the docs. Learn to read both.
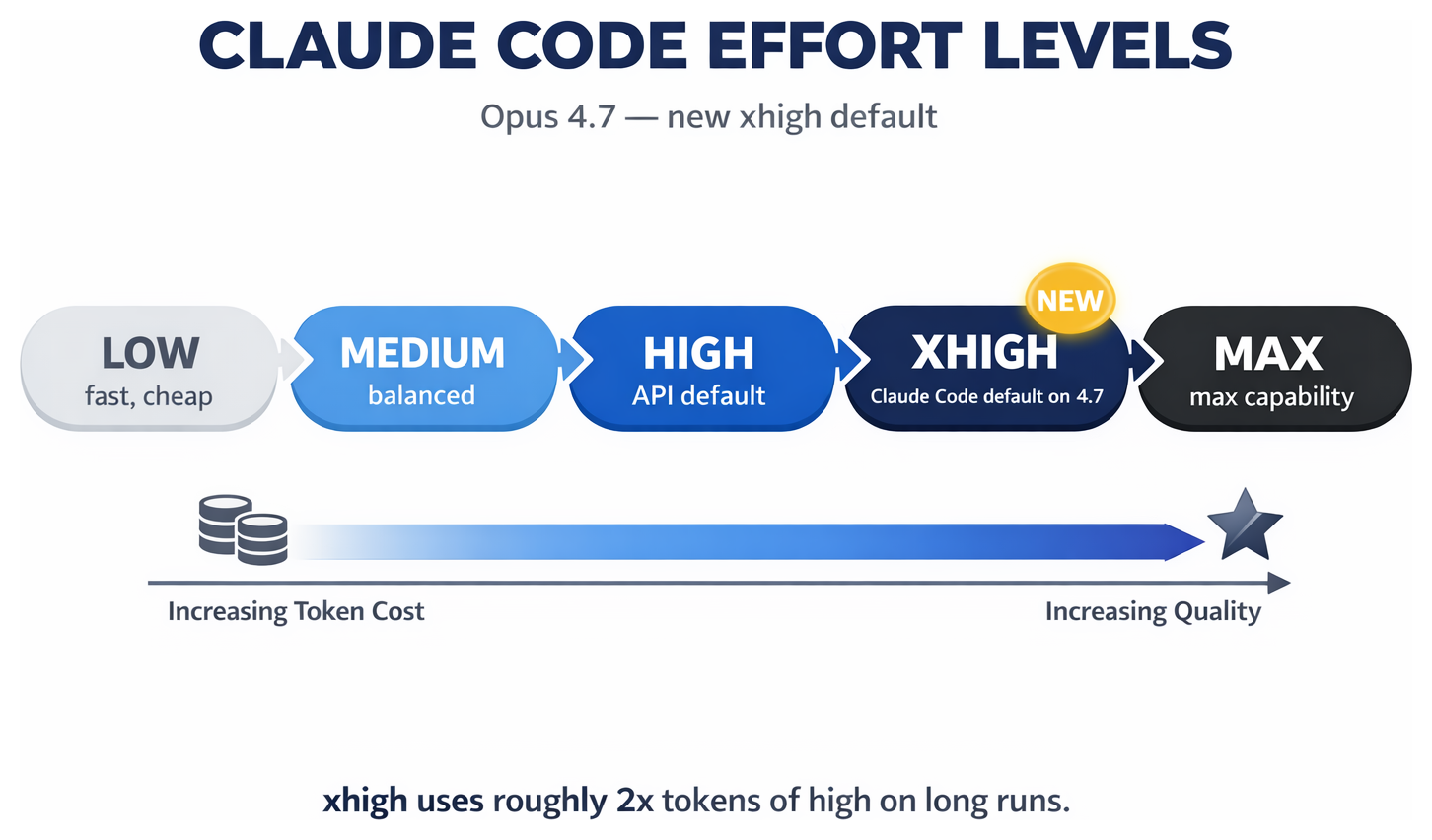
xhigh Is the New Default — and Your Bill Might Jump
Claude has had effort levels for a while — low, medium, high, max — that tell the model how hard to think about a response. Opus 4.7 adds a new one between high and max: xhigh.
And in Claude Code, xhigh is now the default. Anthropic's exact words: "In Claude Code, we've raised the default effort level to xhigh for all plans."
On paper that's free — the per-token price hasn't changed. In practice, there are two multipliers stacking on top of each other:
- Third-party testing suggests
xhighuses roughly twice the tokens ofhighon long agentic runs. - The new tokenizer in 4.7 produces 1.0 to 1.35 times more tokens for the same text versus 4.6.
Put those together and the same piece of work chews through roughly 2–2.7× more tokens than it did last week. If you're on the Anthropic API that's a real bill increase. If you're on a Pro or Max subscription — which most of us are — you'll hit your usage limits much faster. Either way, xhigh is not actually free just because the per-token price stayed the same.
Worth checking your usage over the first few days, or just dial it back. Four ways, in priority order (env var wins):
# In the TUI — interactive $ /effort high # Per-session flag $ claude --effort high # Environment variable (highest precedence) $ export CLAUDE_CODE_EFFORT_LEVEL=high
Or persist it in ~/.claude/settings.json:
{ "effortLevel": "high" }
My own config is on high, not xhigh — partly because I want predictable bills, and partly because high was the default when I set this up and the upgrade didn't overwrite it. Worth checking your settings: the "default" only applies if you haven't set it yourself.
When to use each level is a judgment call, but a starting heuristic: xhigh or max for tricky refactors and hard debugging, high for most day-to-day work, medium or low for quick edits and single-line fixes.
Auto Mode: Claude Decides for You (With a 17% False-Negative Rate)
Auto mode isn't new to this release — it was a research preview in earlier versions — but with 4.7 it's been extended to Max users running Opus 4.7 specifically.
The idea: instead of approving every tool call Claude wants to make, you let it decide. A separate classifier model (running on Sonnet 4.6, server-side) reviews each action and blocks anything that looks risky — curl | bash, pushes to main, mass file deletion, IAM changes, sensitive data leaving your machine.
This is genuinely safer than --dangerously-skip-permissions, which just skips prompts and fires everything. Auto mode still has a classifier between Claude and your system. It also strips Claude's own reasoning from the classifier input so the agent can't argue itself past the gate.
Anthropic also publish the honest number: 17% false-negative rate on their internal "overeager action" test set. One in six genuinely dangerous actions slips through the classifier.
My take, as someone who's spent 30 years in security: auto mode is a reasonable tool for lower-stakes work — personal projects, throwaway scripts, isolated devcontainers. It is not a substitute for reviewing changes to production systems, shared infrastructure, or anything touching money, credentials, or customer data. The classifier is a safety net, not a safety guarantee.
A few specifics if you want to try it:
- Enable with
claude --permission-mode auto, or"defaultMode": "auto"insettings.json. - Pro plans don't get it. Max does. Team, Enterprise, and API accounts get it on Opus 4.6 and 4.7.
- Hooks still fire. There's a new
PermissionDeniedhook that fires when the classifier blocks something — useful for logging or adding your own guardrails. - Broad allow rules like
Bash(*)are dropped automatically when auto mode is on, then restored on exit.
/ultraplan: Plan Big Tasks in the Cloud
Technically /ultraplan shipped a week before Opus 4.7 — in Claude Code 2.1.92 (around 6-10 April). But most people missed it, so it's worth covering.
It works the same way /ultrareview does structurally: you hand off a task to Claude Code on the web, a remote session drafts a plan, and you review it in a browser with inline comments and iteration. When you're happy, the approved plan either executes in the cloud (output: a GitHub PR) or "teleports" back to your terminal for local implementation.
Good for: implementation planning for real engineering work — migrations, refactors, feature decomposition. The canonical example in Anthropic's docs is /ultraplan migrate the auth service from sessions to JWTs.
A few things to know:
- Requires a GitHub repository connected to Claude Code on the web. Not available on Bedrock, Vertex, or Foundry.
- Pro, Max, Team, and Enterprise plans are supposed to have access — though there's currently an open bug (GitHub issue #49510) where some Max 20x users can't see the command at all.
- Anthropic haven't published per-run pricing — unusual for a paid cloud feature. Until they do, assume it eats into your plan's usage rather than billing separately.
Under-the-Hood Changes Worth Knowing
Three things that aren't headline features but will catch you out if you don't know about them.
Adaptive thinking is now the only thinking mode on 4.7. If you use the Claude API with a manual thinking budget, that call will return a 400 error on Opus 4.7. You have to migrate to adaptive thinking — Claude decides per turn how much to think:
// Before (Opus 4.6) — returns 400 on 4.7
{
"thinking": {
"type": "enabled",
"budget_tokens": 32000
}
}
// After (Opus 4.7) — Claude decides per turn
{
"thinking": {
"type": "adaptive"
}
}Also, the default display changed from "summarized" to "omitted", so your thinking traces disappear unless you explicitly ask for them. Set display: "summarized" if you want to see the reasoning.
Long-context retrieval got worse past 256K tokens. Remember that MRCR regression from the table at the top — 78.3% down to 32.2% at 1M tokens. Anthropic dispute the benchmark (they say it "overweights distractor-stacking tricks"), and the Graphwalks improvement shows 4.7 reasons better across long context even when it recalls worse. Practical advice: for retrieval-heavy jobs over 256K — synthesising findings from many large documents, say — Opus 4.6 may still be the better choice. Claude Code itself should be fine because it auto-compacts before you hit those lengths.
High-res vision is meaningfully better. Image resolution support jumped from 1,568 pixels on the long edge to 2,576 — about 3.3 times more pixels. If you build browser agents, document readers, or anything that works from screenshots, this matters. Coordinates also now come back in the image's own pixel space, so UI automation doesn't need rescale maths.
Should You Upgrade?

| If you mainly… | Use |
|---|---|
| Write code and use agents | 4.7 — the gains are real |
| Do heavy long-context retrieval (>256K) | Stay on 4.6 for retrieval jobs |
| Drive browser/computer-use automation | 4.7 — the vision jump is big |
| Use the API with fixed thinking budgets | 4.7 — but budget a migration day |
| Want to stretch your Pro/Max usage limits | 4.7 is fine, but drop effort to high |
My short answer: yes, switch to 4.7 for most things, but dial effort back to high unless you're hitting a genuine wall, and route any big long-context retrieval back to 4.6 until Anthropic's position on MRCR is clearer.
What I'd Do This Week
- Check your
settings.json. Confirm you're on the effort level you actually want. If you upgraded from 4.6 and didn't touch it, you're probably not onxhigh. If it's a fresh install, you probably are. - Try
/ultrareviewon a small repo first. I couldn't get it to launch on my 1.7 GB SATs project — the error doesn't tell you the repo is too big. If you maintain a large repo, start with something smaller before burning free runs. - If you hit a 400 error on the Claude API, check whether you're still sending
thinking: {type: "enabled", budget_tokens: N}. Migrate it to adaptive. - If you're on Max, try auto mode on a personal project — not a production system. See how much it blocks you; decide if the 17% false-negative rate is a risk you can live with.
- Don't treat
xhighas free just because pricing stayed flat. Sub limits get hit faster, API bills scale up. Watch your first few days before committing to it as default.
I'll update this article as I spend more time with the new features — particularly /ultrareview on a real PR. If you want the first look at that update, subscribe to the StationX newsletter or join my Circle community.
Claude Opus 4.7 FAQ
What is Claude Opus 4.7?
Claude Opus 4.7 is Anthropic's flagship coding and agentic model, released on 15 April 2026. It keeps Opus 4.6 pricing ($5 per million input tokens, $25 per million output) but brings meaningful jumps on coding benchmarks (SWE-Bench Pro 53.4% to 64.3%), a new xhigh effort level, the /ultrareview slash command, improved vision, and a new tokenizer.
Is Claude Opus 4.7 free?
No. If you're on the Anthropic API it uses the same pricing as Opus 4.6: $5 per million input tokens and $25 per million output tokens. If you're on a Pro or Max Claude Code subscription, Opus 4.7 is included — you pay your usual monthly fee. Either way, the same piece of work will use roughly 2–2.7× more tokens than before (new tokenizer plus the xhigh default), so API bills go up and subscription usage limits get hit faster.
How do I use /ultrareview in Claude Code?
You need a git repository with a GitHub remote, commits ahead of main, a Claude.ai login (not an API key), and a small enough repo to bundle (my 1.7 GB SATs Revision repo was rejected with a generic 'failed to launch' error). Run /ultrareview on your current branch, or /ultrareview followed by a PR number to review a specific pull request. Pro and Max users get three free trial runs; beyond that each run costs around $10-20 and takes 10-20 minutes. If you need to review an existing codebase that isn't in a PR, use /review instead — it runs locally with no cloud requirement.
What is xhigh effort in Claude Code?
xhigh is a new effort level between high and max, exclusive to Opus 4.7. Claude Code defaults to xhigh on Opus 4.7 for all plans. It tells the model to spend more tokens on reasoning, tool calls, and output — third-party testing shows roughly 2x token usage versus high. Dial back with /effort high in the TUI, CLAUDE_CODE_EFFORT_LEVEL=high environment variable, or effortLevel: "high" in settings.json.
What's the difference between Claude Opus 4.7 and 4.6?
Opus 4.7 is meaningfully better for coding (SWE-Bench Pro +10.9 points), multi-hop reasoning (Graphwalks +19.9), computer use (OSWorld +5.3), and vision (3.3x more image pixels). It's worse on very long-context recall — MRCR at 1M tokens dropped from 78.3% to 32.2%, which Anthropic disputes as a benchmark issue. Practical advice: use 4.7 for coding and agentic work, use 4.6 for retrieval-heavy tasks over 256K tokens.
Is adaptive thinking required on Claude Opus 4.7?
Yes. Manual thinking budgets (thinking: {type: "enabled", budget_tokens: N}) return a 400 error on Opus 4.7. You must migrate to thinking: {type: "adaptive"}, where Claude decides per turn how much to think. Note the silent default change: 4.7 defaults display to "omitted" where 4.6 defaulted to "summarized" — set display: "summarized" explicitly if you want to see reasoning traces.
What is auto mode in Claude Code?
Auto mode lets Claude make tool-call decisions on your behalf. A separate classifier model reviews each action and blocks risky operations like curl | bash, pushes to main, mass deletions, or IAM changes. It's safer than --dangerously-skip-permissions because there's an active gate, but Anthropic publish a 17% false-negative rate on their internal red-team set — one in six risky actions can still slip through. Enable with claude --permission-mode auto (Max on Opus 4.7; not available on Pro).
Should I upgrade from Claude Opus 4.6 to 4.7?
For coding, agentic work, computer use, or vision tasks: yes, the gains are real. For long-context retrieval above 256K tokens: stay on 4.6 until the MRCR regression is resolved. For cost-sensitive chat: upgrade but drop effort to high. If you use the Anthropic API with fixed thinking budgets, budget a migration day because manual budget_tokens no longer works on 4.7.
About the Author

Nathan House, Founder & CEO of StationX
Nathan House has 30 years of hands-on cybersecurity experience and is Cambridge-educated, holding CISSP, CISA, CISM, OSCP, CEH, and SABSA. He founded StationX in 1999 — one of the UK’s first cybersecurity companies — and has secured £71 billion in UK mobile banking transactions and the London 2012 Olympics, advising clients including Microsoft, Cisco, BP, Vodafone, and VISA. He authored the world’s most popular cybersecurity course — a #1 Udemy bestseller taken by over 500,000 students — and was named Cyber Security Educator of the Year 2020, AI Security Educator of the Year, and a UK Top 25 Security Influencer 2025. A DEF CON speaker and featured expert on CNN, Fox News, NBC, and the BBC, Nathan leads StationX’s training of more than half a million students worldwide.
